Laste ned presentasjonen
Presentasjon lastes. Vennligst vent

2
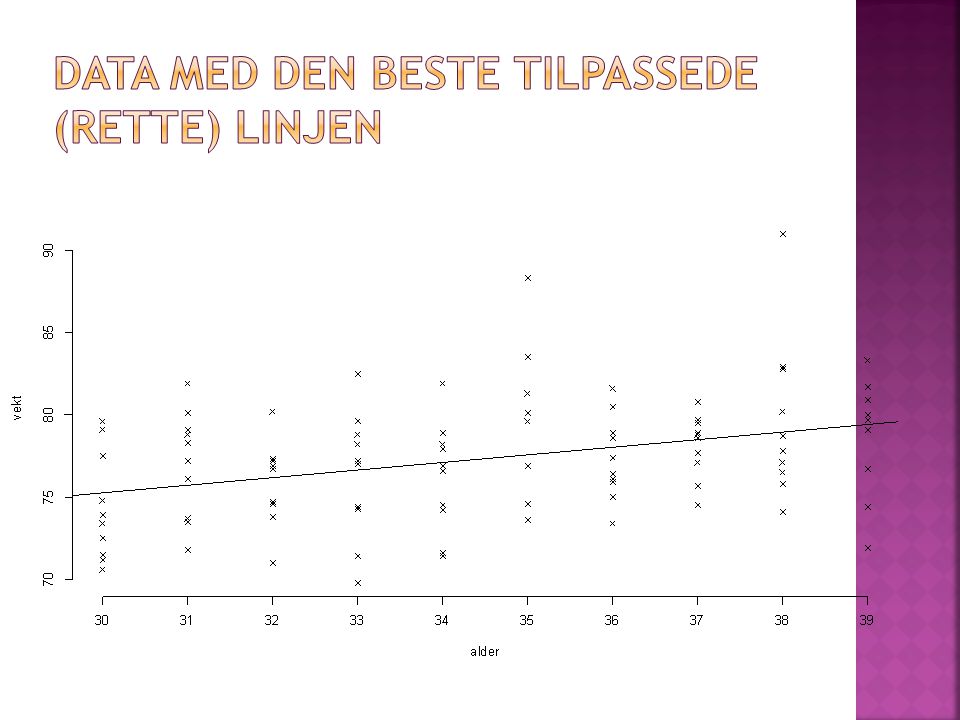
Vi ønsker å tilpasse en rett linje gjennom dataskyen Denne linjen skal ha den beste tilpasningen (minst feil) til data
 til data")
3
Trendlinje Disse avvikene skal minimeres

4
Avhengig variabel: y Uavhengig variabel x y = ax + b I regresjonsanalyser:

5
"Noise" "Structure + Noise" "Structure"

6
Y=β 0 +β 1 X Litt tidkrevende å regne ut. Dette gjøres vanligvis av et dataprogram Enkel når vi først vet β 1

7
1. Det finnes en y-verdi for hver x-verdi 2. y-variabelen er normalfordelt 3. Gjennomsnittene til disse normalfordelingene ligger på regresjonslinja og de har samme standardavvik 4. y-variablen er kun en funksjon av x

8
Vi skal se på vekt som en funksjon av alder Datasettet er ikke reelt, men gir oss en god innføring i regresjonsanalyse Vi har registert alder og vekt hos 100 menn i 30 årene (10 fra hvert årsintervall) Vi ønsker å bruke disse dataene til å si noe om hvor mye denne gruppen menn i Norge legger på seg i løpet at et år
 Vi ønsker å bruke disse dataene til å si noe om hvor mye denne gruppen menn i Norge legger på seg i løpet at et år")
10
Først regner vi ut summen over brøkstreken Deretter under =825 β 1 =380.2/825=0.46 Y= 61.47 +0.46*x = 380.2 β 0 = 77.34 -0.46*34.5 =61.47

11
lm(formula = vekt ~ alder) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 61.4407 4.1298 14.877 < 2e-16 *** alder 0.4608 0.1193 3.863 0.000201 *** Bruk informasjonen over til å prediktere vekt ved alder 35, 40 og 1 år
 (Intercept) < 2e-16 *** alder *** Bruk informasjonen over til å prediktere vekt ved alder 35, 40 og 1 år.")
14
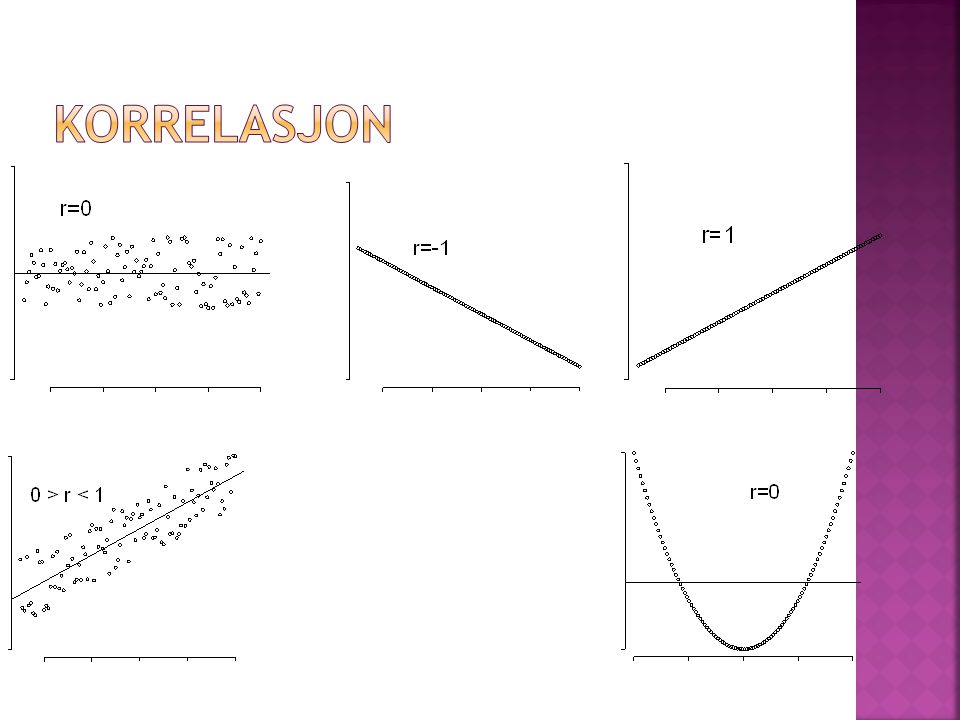
Korrelasjonskoeffesienten r og r 2 r beregnes via formelen r gir oss antall standardavvik y endrer seg dersom x endres med ett standardavvik. r har grensene -1 og 1

15
Måler hvor mye av variasjonen den lineære modellen forklarer SS (sum of squares) "Y minus rød linje" SSE (Residual sum of squares) "Y minus grønn linje"
 Y minus rød linje SSE (Residual sum of squares) Y minus grønn linje")
16
r 2 = SS – SSE SS SS = Total variasjon SSE = Resterende (Residual) variasjon SS-SSE = SSR (Sum of Square Regresjon)
 variasjon SS-SSE = SSR (Sum of Square Regresjon)")
17
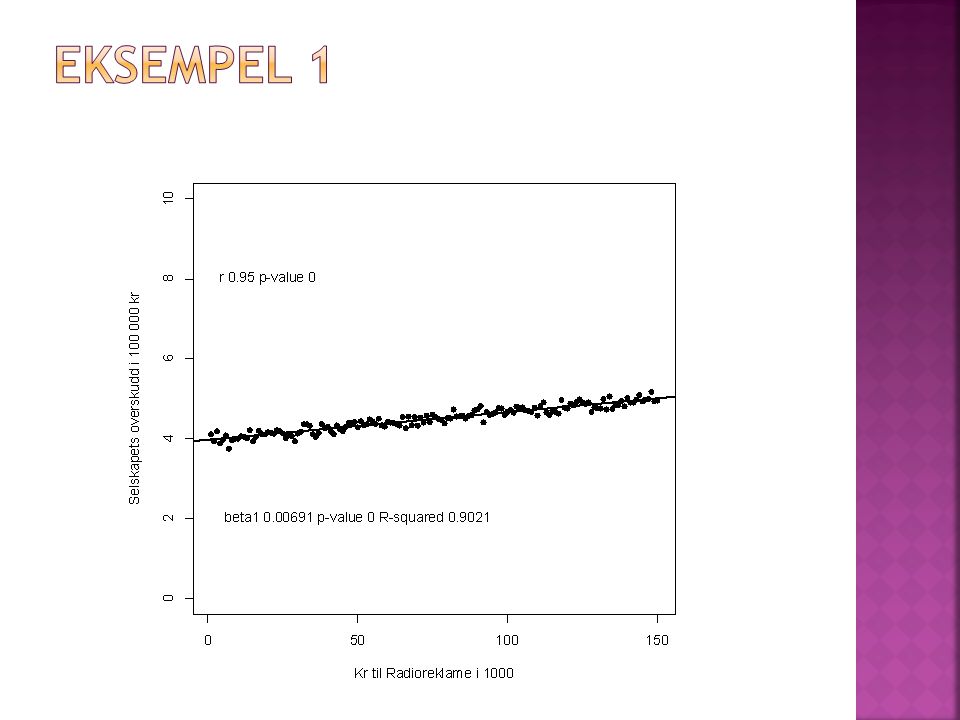
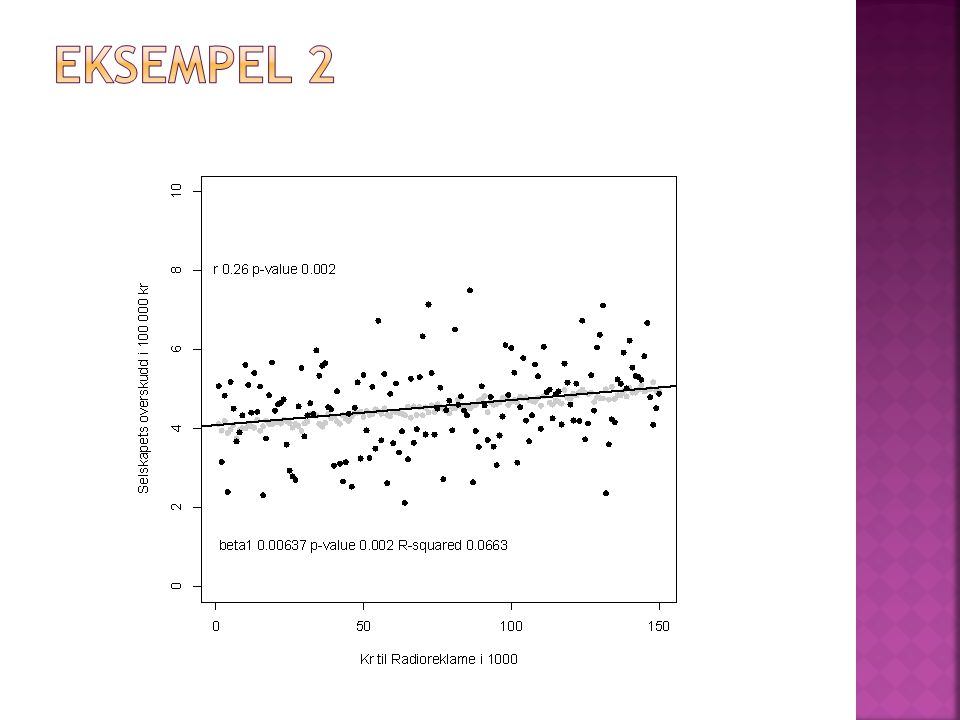
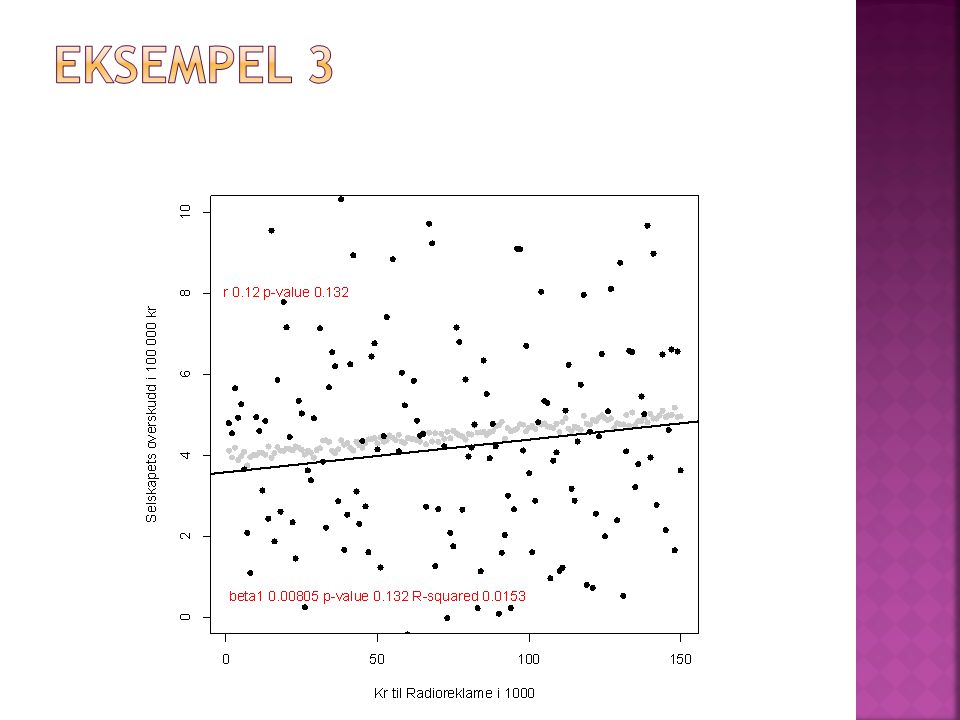
Gitt data for antallet kroner brukt på radioreklame og overskudd i 150 små bedrifter Sammenhengen mellom x (kroner i reklame) og y (Inntekter i 1000 kr) er det samme i alle tre eksemplene. “Støyen" er ulik Vil du anbefale meg som bedriftsleder å invistere i radioreklame, og hvor mye?

21
Lineær regresjon lar oss beregne den best tilpassede rette linjen mellom datapunktene til to variabler I noen datasett finnes det flere lineære sammenhenger Vi ønsker å justere for effekten av disse, og vise hvilke som er signifikante effekter

22
Basketball Vi har mål høyden til 100 basketballspillere og vi har et mål på hvor mange poeng de gjennomsnittlig har scoret i løpet av en sesong Vi tror det er en sammenheng mellom høyde og gjennomsnitlig poengfangst

23
Coefficients: EstimateStd. Errort value Pr(>|t|) (Intercept) -54.63216 8.26963-6.606 2.06e-09 height 0.40114 0.04162 9.638 7.40e-16
 (Intercept) e-09 height e-16.")
24
Basketball Vi vet i tillegg vekten til basketballspillerene Vi tror også det er en sammenheng mellom vekt og gjennomsnittlig poengfangst (Tyngre = mer muskler)
")
25
Coefficients: Estimate Std. Errort value Pr(>|t|) (Intercept) -18.2857 5.1093 -3.5790.000538 basket$weight 0.4145 0.0488 8.493 2.22e-13
 (Intercept) basket$weight e-13.")
26
To variabler som korrelerer med score Vi ønsker å oppgi effekten av gjennomsnitlig score for høyde justert for vekt Eller Gjennomsnittlig score for vekt justert for høyde

28
Generell formel Y hatt = skjæringspunkt +stigningstall variabel1 * verdi variabel 1 +....+ stigningstall variabel n *verdi variabel n Hvis regresjonsparameteret β n er signifikant forskjellig fra null inkluderer vi denne termen i analysen vår

29
Call: lm(formula = basket$score ~ basket$weight + basket$height) Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -48.64826 8.39305 -5.796 8.44e-08 *** basket$weight 0.17744 0.07032 2.523 0.0133 * basket$height 0.27766 0.06356 4.369 3.14e-05 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.332 on 97 degrees of freedom Multiple R-squared: 0.5185,Adjusted R-squared: 0.5086 F-statistic: 52.23 on 2 and 97 DF, p-value: 4.031e-16
 (Intercept) e-08 *** basket$weight * basket$height e-05 *** --- Signif. codes: 0 ‘***’ ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: on 97 degrees of freedom Multiple R-squared: ,Adjusted R-squared: F-statistic: on 2 and 97 DF, p-value: 4.031e-16.")
Liknende presentasjoner











 Innførte koordinatsystemet>")
>")

>")



>")



