Laste ned presentasjonen
Presentasjon lastes. Vennligst vent

1
Stian Grønning Master i samfunnsøkonomi Daglig leder i Recogni

2
4 timer 4 deler Basics t- test Anova Regresjon

3
Populasjon Eksempel: Alle studenter i Tromsø Populasjon Eksempel: Alle studenter i Tromsø Prøve / Sample Eksempel: Auditorium Prøve / Sample Eksempel: Auditorium Statistikk Prediksjon

4
Hvorfor? Kostnader Gjennomførbarhet Det kan være utfordringer med å gjøre et godt utvalg!

5
Vi ønsker å si noe om tendensen i data via et mål for middelverdi og et mål for variasjon Gjenomsnitt Median Typetall (mode) Range Varians / standardavvik
 Range Varians / standardavvik")
6
Ved små utvalg er gjennomsnittet følsomt for ekstremverdier Gjennomsnittet sier ingenting om datastrukturen som ligger bak!

7
Typetall er hyppigste verdi Median, midterste verdi (ofte viktigere enn gjennomsnittet) Lite følsomme for ekstremverider
 Lite følsomme for ekstremverider")
11
Responsvariabel Y Forklaringsvariabel X

12
Responsvariabel Y Responsvariabel Y Forklaringsvariabel X Forklaringsvariabel X Kontinuerlig Diskret Kontinuerlig t-test ANOVA t-test ANOVA Tabulært design χ 2 Tabulært design χ 2 Regresjon / Korrelasjon Log Reg

13
Varians Standard- avvik Populasjon Utvalg

14
Standardfeilen er et mål på hvor usikkert et gjennomsnitt er Standardavvik sier noe om spredningen til dataene Standardfeilen minker med n

15
Populasjon = 100 000 Vi vet blodtrykket til alle individene Gjennomsnitt = 78.2 Standardavvik = 9.4 Normalfordeling Populasjon = 100 000 Vi vet blodtrykket til alle individene Gjennomsnitt = 78.2 Standardavvik = 9.4 Normalfordeling Utvalg = 10 Utvalg = 100 Utvalg = 1000 Utvalg = 10000

16
Populasjonen Gj snitt= 78.2 Standardavvik =9.4 Populasjonen Gj snitt= 78.2 Standardavvik =9.4 n10 Gj snitt 79.1 Standardavvik 9.2 SE2.9 Konfidensintervall73.4 – 84.8 n10 Gj snitt 79.1 Standardavvik 9.2 SE2.9 Konfidensintervall73.4 – 84.8 n10 000 Gj snitt 78.2 Standardavvik 9.4 s.e.0.094 Konfidensintervall78.0 – 78.4 n10 000 Gj snitt 78.2 Standardavvik 9.4 s.e.0.094 Konfidensintervall78.0 – 78.4 n1000 Gj snitt 78.2 Standardavvik9.6 s.e.0.3 Konfidensintervall77.6 – 78.8 n1000 Gj snitt 78.2 Standardavvik9.6 s.e.0.3 Konfidensintervall77.6 – 78.8 n100 Gj snitt 77.8 Standardavvik 7.8 SE0.78 Konfidensintervall76.3 – 79.3 n100 Gj snitt 77.8 Standardavvik 7.8 SE0.78 Konfidensintervall76.3 – 79.3

17
Det finnes flere typer fordelinger. Poisson-, binomial-, normal-, t-, z-, f- osv. Vi skal fokusere på

18
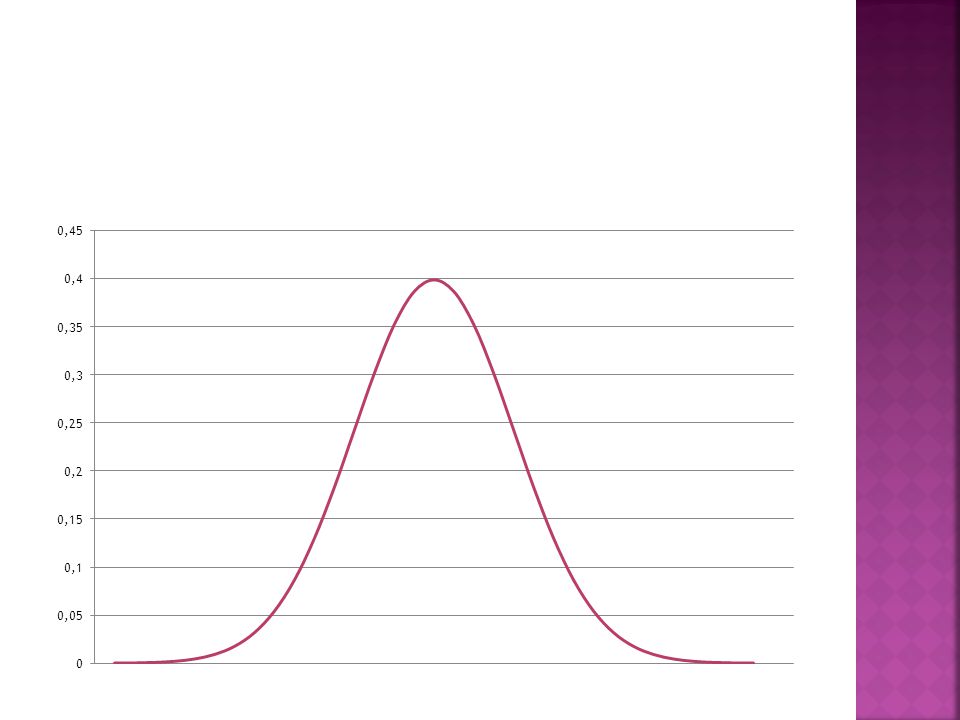
Arealet under kurven = 1

19
Ved mange analyser forutsetter vi at data er normalfordelte, dette stemmer bra for en del variabler (F.eks høyde og vekt), andre variabler kan ha en annen fordeling. Før tester gjennomføres undersøker vi for normalitet i data Brudd på forutsetningen om normalfordelingen i data trenger ikke være veldig alvorlig

20
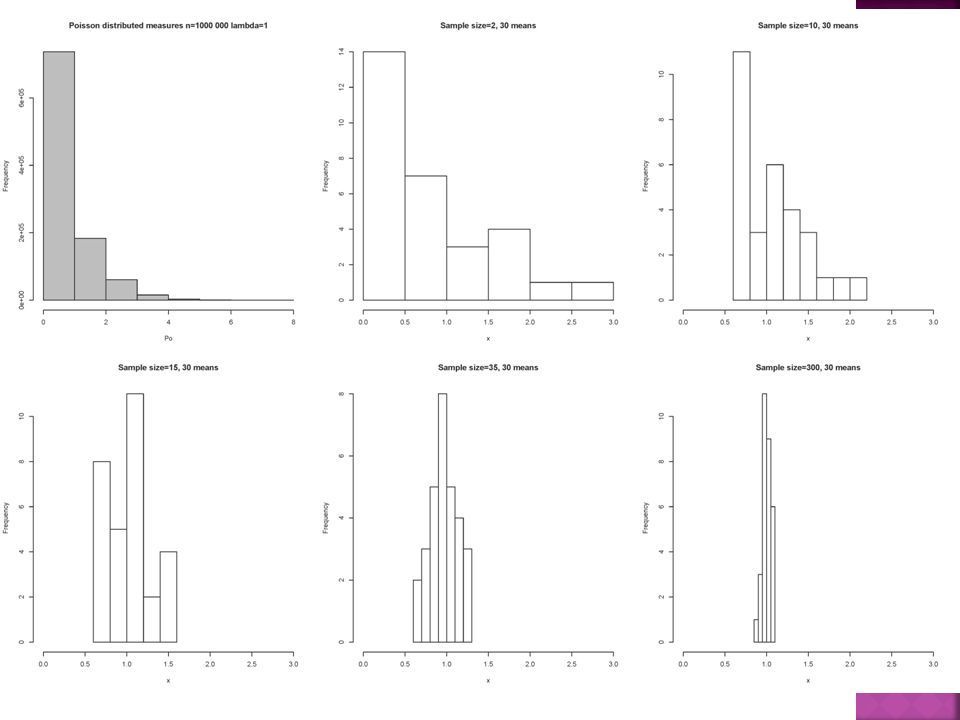
Gjennomsnittene til flere prøver er normalfordelte hvis antallet individer i hver prøve er stort nok. Mellom 15 – 30 prøver avhengig av fordelingen til populasjonen Et eksempel

21
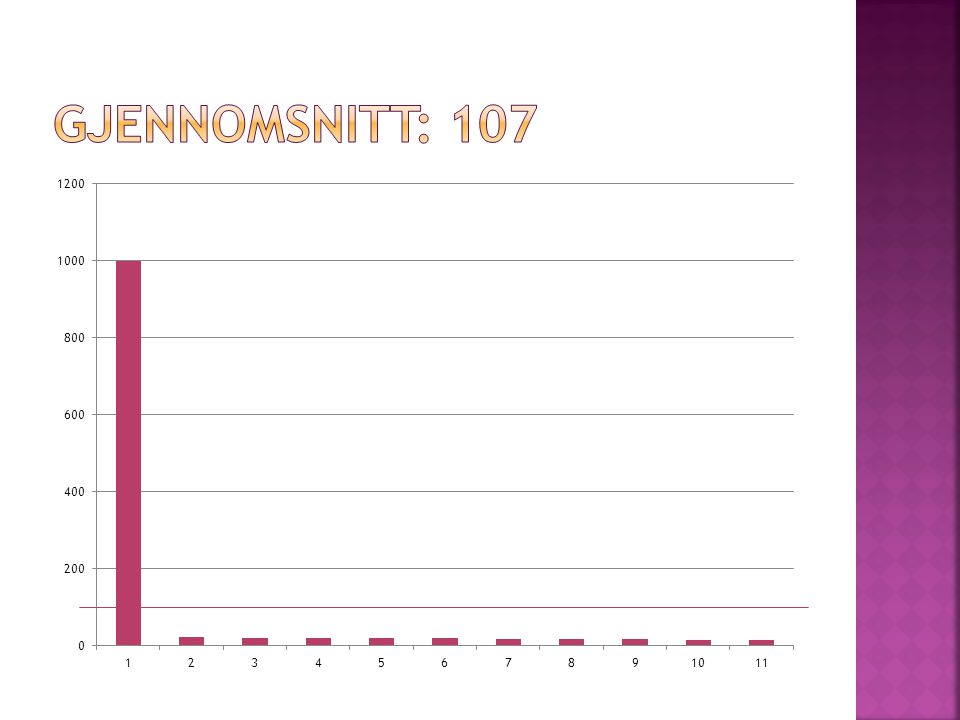
Vi har 1 000 000 mål på hvor mange økonomistudenter som løser statistikkoppgaver mellom 19:00 og 20:00med undersøkelser å oppnå datasettet) Gjennomsnitlig jobber 1 student med statistikk på denne timen. Data er poisson- fordelte og ser slik ut

22
Populasjon 1000 000 dager med måling Populasjon 1000 000 dager med måling Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Prøve / Sample Trekker ut n tilfeldige dager Regner gjennomsnitt Hvor stort utvalg i hver prøve???

23
3 3 10 12 11 4 4 1 1 6 6 5 5 15 7 7 13 14 8 8 9 9 2 2 GjennomsnittGjennomsnitt GjennomsnittGjennomsnitt 1 0 2

26
Blodtrykk gjennomsnitt: 70 -75 Høyde gjennomsnitt i cm: 170-175 Vi ønsker å standardisere målene slik at de blir sammenlignbare. Standard Normalfordeling x = observert verdi μ = gjennomsnitt σ= standardavviket Dette transformerer data til en normalfordeling med gjennomsnitt 0 og varians 1

27
En simulert fordeling av menn sin høyde gjennomsnitt 175 og standardavvik= 7

28
Gitt vår fordeling med gjennomsnitt 175 og varians 7 Hva er sansynligheten for at en person skal være 189 cm eller høyere? Først standardiserer vi (189 -175)/7=2 189 er 2 standardavvik ifra 0 0.0228 ev 2.3% sansynlighet for at noen skal være 189 cm eller høyere Samtidig er det 2.3 *2 = 4.6% sansynlighet for at en person er 2 standardavvik større eller mindre en gjennomsnittet Tosidig test, dette kommer vi til å bruke en del
/7=2 189 er 2 standardavvik ifra ev 2.3% sansynlighet for at noen skal være 189 cm eller høyere Samtidig er det 2.3 *2 = 4.6% sansynlighet for at en person er 2 standardavvik større eller mindre en gjennomsnittet Tosidig test, dette kommer vi til å bruke en del.")
29
Hva er proporsjonen av menn med høyde mellom 170 og 185 cm? Fordeling ~N(175,7) først proporsjonen under 170 z=(170-175)/7= -0.71 fra tabell over standard normalfordelingen finner vi at dette tilsvarer 0.2389 eller 23.9% har en lavere høyde en 170 cm Proporsjonen over 185 z=(185-175)/7=1.42 proporsjonen av menn over 185cm =0.0778 eller 7.8% Siden arealet totalt er 1.0 blir proporsjonen av menn mellom 170cm og 185cm 1-0.2389-0.0778=0.6833 68.3% av alle menn har en høyde mellom 170 og 185cm Med utgangspunkt i vår fordeling!!!!!!!
 først proporsjonen under 170 z=( )/7= fra tabell over standard normalfordelingen finner vi at dette tilsvarer eller 23.9% har en lavere høyde en 170 cm Proporsjonen over 185 z=( )/7=1.42 proporsjonen av menn over 185cm = eller 7.8% Siden arealet totalt er 1.0 blir proporsjonen av menn mellom 170cm og 185cm = 68.3% av alle menn har en høyde mellom 170 og 185cm Med utgangspunkt i vår fordeling!!!!!!!.")
30
Fordelingen ~N(175,7) Hvilket høydeintervall representerer 10% av den høyeste befolkningen? Bruk normalfordelingstabell til å finne nærmeste verdi 10.03% tilsvarer z=1.28 Z=1.28 tilsvarer x=(1.28*7) +175 = 183.96 ≈ 184 cm eller høyere tilsvarer ti prosent av den høyeste befolkningen
 +175 = ≈ 184 cm eller høyere tilsvarer ti prosent av den høyeste befolkningen.")
31
Først finner vi sannsynligheten for at en student leser mindre en 400 ord. Z=400-950/220 Z=-2.5, fra SND tabell blir dette 0.0062 Sannsynligheten for at det er to studenter som leser mindre enn 400 ord blir 0.0062 * 0.0062 =0.000038

32
68.26% av data ligger innenfor± 1 standardavvik

33
2.5% av fordelingen 95% av data ligger ±1.96 standardavvik fra gjennomsnitt

34
Hvis vi tar flere prøver fra en populasjon vil 95% av disse ligge ±1.96 standardfeil fra gjennomsnittet Vi antar at vi har en tilstrekkelig stor utvalgsstørrelse fra Gjennomsnitt -1.96 s.e til Gjennomsnitt +1.96 s.e er det vi kaller konfidensintervallet Vi kan si at 95% av beregnede konfidensintervall inneholder det ukjente populasjonsgjennomsnittet. Hvis vi beregner 20 konfidensintervall vil vi forvente at 1 av dem ikke inneholder populasjonsgjennomsnittet. Vi kan IKKE si at populasjonsgjennomsnittet ligger innenfor konfidensintervallet med 95% sansynlighet

35
Populasjon 10 000 studenter i Tromsø Måleenhet antall kontakter i mobiltelefon ~N(200,25) Populasjon 10 000 studenter i Tromsø Måleenhet antall kontakter i mobiltelefon ~N(200,25) Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter 20 prøver
 Populasjon studenter i Tromsø Måleenhet antall kontakter i mobiltelefon ~N(200,25) Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter Prøve 15 studenter 20 prøver")
36
I snitt vil 1 av 20 prøver ha et 95% konfidensintervall som ikke inneholder populasjonens ukjente gjennomsnitt

38
Vi mistenker at mørketiden har en innvirkning på søvnmønster Vi vil undersøke dette ved å se på to populasjoner 1. Studenter i Tromsø 2. Studenter i Oslo Vi tenker oss at det er undersøkt tilsammen 100 studenter og antall timer søvn pr. døgn er registrert (målinger foretatt i Desember)
.")
39
Eksempel Hypotese (H A ) Studenter i Tromsø sover i snitt mer en studenter i Oslo i mørketiden Nullhypotese (H 0 ) Det er ingen forskjell i gjennomsnittlig søvnmengde mellom de to gruppene Vi vil teste hvor sansynlig det er å få en forskjell like stor, eller større en vårt observerte resultat hvis nullhypotesen er sann
 Studenter i Tromsø sover i snitt mer en studenter i Oslo i mørketiden Nullhypotese (H 0 ) Det er ingen forskjell i gjennomsnittlig søvnmengde mellom de to gruppene Vi vil teste hvor sansynlig det er å få en forskjell like stor, eller større en vårt observerte resultat hvis nullhypotesen er sann")
40
Populasjon 1 Gjsnitt =? Std = ? Populasjon 1 Gjsnitt =? Std = ? Populasjon 2 Gjsnitt=? Std=? Populasjon 2 Gjsnitt=? Std=? Utvalg Sammenligning

41
(Gjennomsnitt1 – Gjennomsnitt 2) ±1.96*Felles standardfeil Utvalg 1 Gj snitt s.e. Utvalg 1 Gj snitt s.e. Utvalg 2 Gj snitt s.e. Utvalg 2 Gj snitt s.e. eller √(s.e. a 2 + s.e. b 2 )
.")
42
Vi mistenker at mørketiden har en innvirkning på søvnmønster Vi vil undersøke dette ved å se på to populasjoner 1. Studenter i Tromsø 2. Studenter i Oslo Vi tenker oss at det er undersøkt tilsammen 100 studenter og antall timer søvn pr. døgn er registrert (målinger foretatt i Desember) Hva er 95% konfidensintervallet for forskjellen mellom disse to gruppene?
 Hva er 95% konfidensintervallet for forskjellen mellom disse to gruppene .")
43
Først regner vi ut diferansen 8.7 – 7.9 = 0.8 Deretter s.e. √(0.29 2 + 0.25 2 ) =0.38 Konfidensintervallet blir da 0.8 ±0.38*1.96 fra 0.055 til 1.54 Vi kan med 95% sansynlighet si at konfidensintervallet 0.055 til 1.54 dekker den (ukjente) sanne forskjellen i mengde søvn mellom de to gruppene GruppeAntallGjennomsnitt timer søvn Standardavviks.e. Tromsø438.71.90.29 Oslo577.91.90.25 Regn ut!!!!!
 =0.38 Konfidensintervallet blir da 0.8 ±0.38*1.96 fra til 1.54 Vi kan med 95% sansynlighet si at konfidensintervallet til 1.54 dekker den (ukjente) sanne forskjellen i mengde søvn mellom de to gruppene GruppeAntallGjennomsnitt timer søvn Standardavviks.e. Tromsø Oslo Regn ut!!!!!.")
44
Vi skal bruke z-tabellen, SND formelen var Denne må skrives om til bruk av to gjennomsnitt og et felles mål på variasjon (s.e.) Felles standardfeil blir
 Felles standardfeil blir")
45
Formelen for z blir dermed Standardfeilen Forskjell i gjennomsnitt =z

46
Forskjell i gjennomsnitt = 0.8 Standardfeilen til de to prøvene er √(0.29 2 + 0.25 2 ) =0.38 z= 0.8/0.38 =2.10 Slå opp i Z tabell Sansynligheten for z>2.10 = 0.01786 Vi bruker en to sidig test, dvs sansynligheten for størelsen på avviket ikke retningen Siden kurven er symmetrisk blir sansynligheten 2*0.01786 = 0.035 Hva gjør vi med nullhypotesen? GruppeAntallGjennomsni tt timer søvn Sds.e. Tromsø438.71.90.29 Oslo577.91.90.25

Liknende presentasjoner











>")


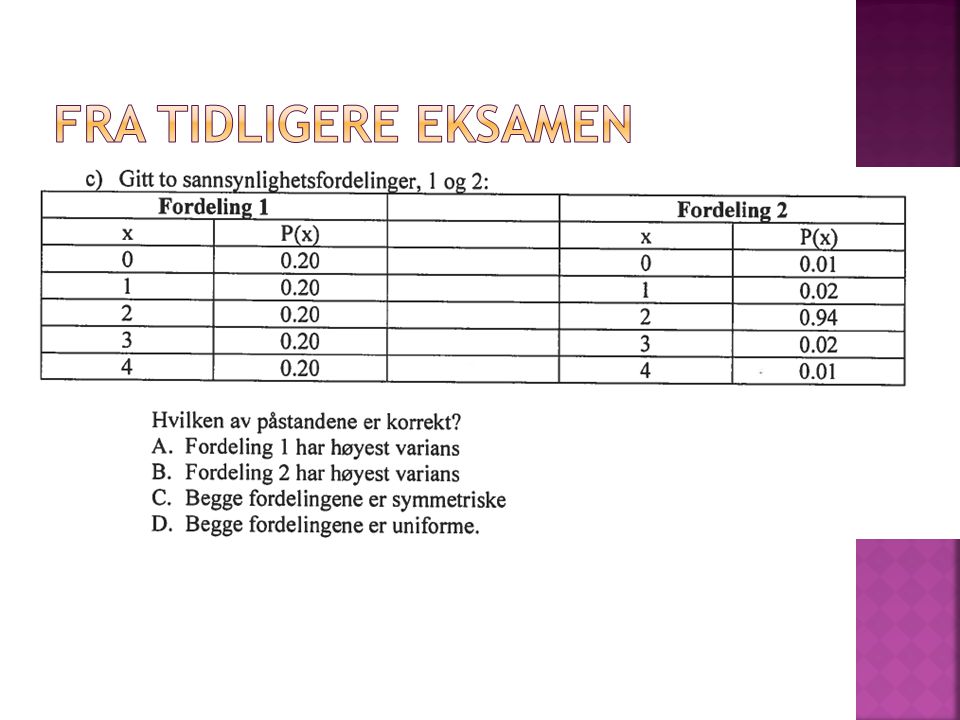
 a)P(T>1)=P(T≠1)=1-P(T=1) = 1-1/6 = 5/6 ≈ 83.3%. Evt. P(T>1)=p(T=2)+P(T=3)+P(T=4)+P(T=5)+ P(T=6)=5/6. P(T=2 | T≠1) = P(T=2 og T≠1)/P(T≠1) = (1/6)/(5/6)>")
Vi anser hvert av de seks utfallene på en terning for å være like sannsynlig og at to ulike terningkast er uavhengige. a)Hva er sannsynligheten.>")





