Laste ned presentasjonen
Presentasjon lastes. Vennligst vent

1
MPI 分布内存并行 程序开发

2
第四章 点对点通信函数 第四章 点对点通信函数 传送机制(两种): 阻塞方式,它必须等到消息从本地送出之后才可 以执行后续的语句,保证了缓冲区等资源的可再 用性; 非阻塞方式,它不须等到消息从本地送出就可以 执行后续的语句,但非阻塞调用的返回并不保证 资源的可再用性。
: 阻塞方式,它必须等到消息从本地送出之后才可 以执行后续的语句,保证了缓冲区等资源的可再 用性; 非阻塞方式,它不须等到消息从本地送出就可以 执行后续的语句,但非阻塞调用的返回并不保证 资源的可再用性。")
3
阻塞通信正确返回后,其后果是: - 该调用要求的通信操作已正确完成 - 该调用要求的通信操作已正确完成 - 该调用的缓冲区可用 - 该调用的缓冲区可用 消息信封要匹配 接收到的消息是最早发送的 非阻塞通信主要用于计算和通信的重叠, 从而提高整个程序执行的效率。

4
MPI 点对点通信函数的参数格式一般如下所示: MPI 消息传递函数参数

5
请求( request ) 请求( request ) 这个参数用于非阻塞发送和非阻塞接收操作。 由于非阻塞操作返回后,数据可能继续存在缓 冲中,由此需要一种机制来检测资源是否可用。 根据该变量调用其它函数完成消息的实际发送 和接收。在 C 程序中,这个参数是指向 MPI_Request 结构的指针。
 请求( request ) 这个参数用于非阻塞发送和非阻塞接收操作。 由于非阻塞操作返回后,数据可能继续存在缓 冲中,由此需要一种机制来检测资源是否可用。 根据该变量调用其它函数完成消息的实际发送 和接收。在 C 程序中,这个参数是指向 MPI_Request 结构的指针。")
6
通讯模式( 4 种): 标准通信模式 (MPI_SEND) 缓存通信模式 (MPI_BSEND) 同步通信模式 (MPI_SSEND) 就绪通信模式 (MPI_RSEND)
: 标准通信模式 (MPI_SEND) 缓存通信模式 (MPI_BSEND) 同步通信模式 (MPI_SSEND) 就绪通信模式 (MPI_RSEND)")
7
标准( standard )模式:对数据的缓冲由 具体 MPI 实现决定,与用户程序无关; 发送操作的正确返回而不要求接收操作收 到发送的数据。 发送操作的正确返回而不要求接收操作收 到发送的数据。 SR 1
模式:对数据的缓冲由 具体 MPI 实现决定,与用户程序无关; 发送操作的正确返回而不要求接收操作收 到发送的数据。 发送操作的正确返回而不要求接收操作收 到发送的数据。 SR 1")
8
缓冲区( buffered )模式:用户定义,使用 和回收缓冲区,不管接收操作是否启动, 发送操作都可以执行,但是必须保证缓冲 区可用。 SR 1 缓冲区 2
模式:用户定义,使用 和回收缓冲区,不管接收操作是否启动, 发送操作都可以执行,但是必须保证缓冲 区可用。 SR 1 缓冲区 2")
9
u 同步 (synchronous) 模式:开始不依赖于 接收进程相应的操作是否启动,但必须 等到接受开始启动发送才可以返回 SR 123123
 模式:开始不依赖于 接收进程相应的操作是否启动,但必须 等到接受开始启动发送才可以返回 SR")
10
u 就绪 (ready) 模式:只有当接收操作已经 启动时,才可以在发送进程启动发送操 作,否则发送将出错。 SR 1212
 模式:只有当接收操作已经 启动时,才可以在发送进程启动发送操 作,否则发送将出错。 SR 1212")
11
例 3 、死锁的发送接收序列 例 3 、死锁的发送接收序列 CALL MPI_COMM_RANK(comm,rank,ierr) CALL MPI_COMM_RANK(comm,rank,ierr) IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) ENDIF ENDIF
 CALL MPI_COMM_RANK(comm,rank,ierr) IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) ENDIF ENDIF")
12
进程 0 进程 1 从进程 1 接收消息 A 向进程 1 发送消息 C 从进程 0 接收消息 B 向进程 0 发送消息 D A B C D

13
例 4 、不安全的发送接收序列 例 4 、不安全的发送接收序列 CALL MPI_COMM_RANK(comm,rank,ierr) IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) ENDIF ENDIF
 IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) ENDIF ENDIF")
14
进程 0 进程 1 从进程 1 发送消息 A 向进程 1 接收消息 C 从进程 0 发送消息 B 向进程 0 接收消息 D A B C D 系统缓冲区

15
程序 5 、安全的发送接收序列 程序 5 、安全的发送接收序列 CALL MPI_COMM_RANK(comm,rank,ierr) IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) ENDIF ENDIF
 IF (rank.EQ.0) THEN IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf,count,MPI_REAL,1, CALL MPI_SEND(sendbuf,count,MPI_REAL,1, tag,comm,ierr) tag,comm,ierr) CALL MPI_RECV(recvbuf,count,MPI_REAL,1, CALL MPI_RECV(recvbuf,count,MPI_REAL,1, tag,comm,status,ierr) tag,comm,status,ierr) ELSE IF (rank.EQ.1) ELSE IF (rank.EQ.1) CALL MPI_RECV(recvbuf,count,MPI_REAL,0, CALL MPI_RECV(recvbuf,count,MPI_REAL,0, tag,comm,status,ierr) tag,comm,status,ierr) CALL MPI_SEND(sendbuf,count,MPI_REAL,0, CALL MPI_SEND(sendbuf,count,MPI_REAL,0, tag,comm,ierr) tag,comm,ierr) ENDIF ENDIF")
16
进程 0 进程 1 从进程 1 发送消息 A 向进程 1 接收消息 C 从进程 0 接收消息 B 向进程 0 发送消息 D A B C D

17
例子 6 例子 6 clock=(myrank+1)%groupsize; anticlock=(myrank+groupsize-1)%groupsize; MPI_Send(buf1,LENGTH,MPI_CHAR,clock,tag,MPI_COM M_WORLD); MPI_Recv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_C OMM_WORLD,&status); 012
%groupsize; anticlock=(myrank+groupsize-1)%groupsize; MPI_Send(buf1,LENGTH,MPI_CHAR,clock,tag,MPI_COM M_WORLD); MPI_Recv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_C OMM_WORLD,&status); 012")
18
改进: 改进: MPI_Isend(buf1,LENGTH,MPI_CHAR,clock,tag,MPI_COMM_WORLD,&req uest); MPI_Recv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_COMM_WORLD,& status); MPI_Wait(&request,&status); --------------------------------- MPI_Irecv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_COMM_WORLD,&r equest); MPI_Send(buf2,LENGTH,MPI_CHAR,clock,tag,MPI_COMM_WORLD); MPI_Wait(&request,&status);
; MPI_Recv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_COMM_WORLD,& status); MPI_Wait(&request,&status); --------------------------------- MPI_Irecv(buf2,LENGTH,MPI_CHAR,anticlock,tag,MPI_COMM_WORLD,&r equest); MPI_Send(buf2,LENGTH,MPI_CHAR,clock,tag,MPI_COMM_WORLD); MPI_Wait(&request,&status);")
19
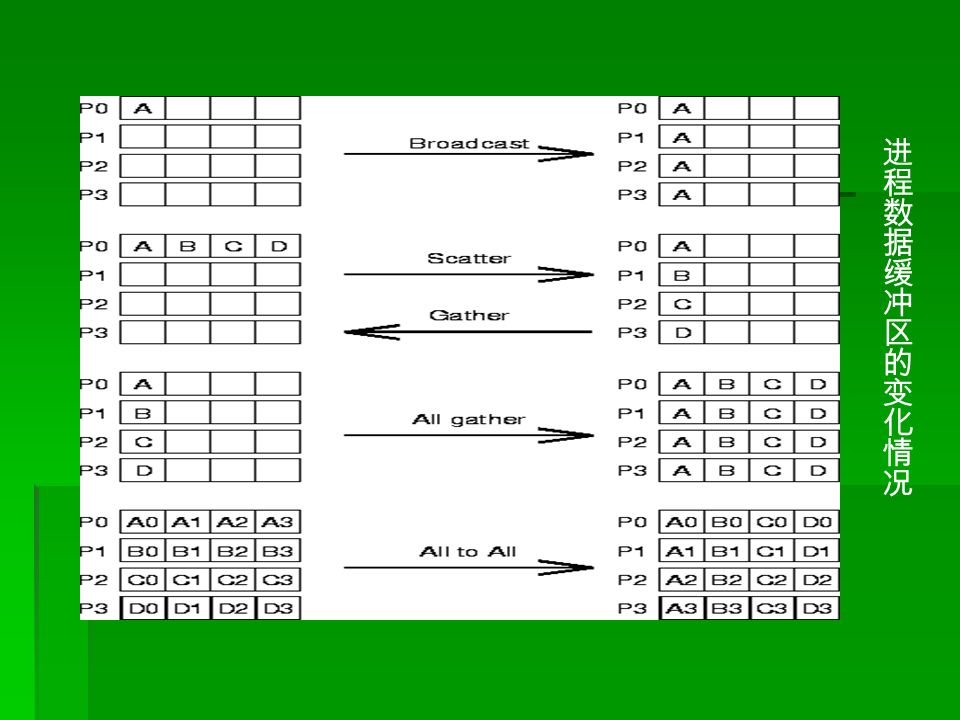
第五章 集合通信函数 l 集合通信是包含在通信因子中的所有进程都 参加操作。 l 集合通信一般实现三个功能 通信:组内数据的传输 通信:组内数据的传输 同步:组内所有进程在特定的地点在执行 同步:组内所有进程在特定的地点在执行 进度上取得一致 进度上取得一致 计算:对给定的数据完成一定的操作 计算:对给定的数据完成一定的操作

20
集合操作的三种类型: 集合操作的三种类型: 同步 (barrier) :集合中所有进程都到达 后,每个进程再接着运行; 数据传递:广播 (broadcast) 、分散 (scatter) 、收集 (gather) 、全部到全部 (alltoall) ; 规约 (reduction) :集合中的其中一个进 程收集所有进程的数据并计算(如:求 最大值、求最小值、加、乘等);
 :集合中所有进程都到达 后,每个进程再接着运行; 数据传递:广播 (broadcast) 、分散 (scatter) 、收集 (gather) 、全部到全部 (alltoall) ; 规约 (reduction) :集合中的其中一个进 程收集所有进程的数据并计算(如:求 最大值、求最小值、加、乘等);")
21
集合通信函数 集合通信函数 MPI_Barrier MPI_Bcast MPI_Scatter MPI_Gather MPI_Scan MPI_Reduce

22
MPI_Barrier() MPI_Barrier() 在组中建立一个同步栅栏。当每个进程都到达 MPI_Barrier 调用后,程序才接着往下执行: MPI_Barrier (comm)
 MPI_Barrier() 在组中建立一个同步栅栏。当每个进程都到达 MPI_Barrier 调用后,程序才接着往下执行: MPI_Barrier (comm)")
23
程序 7 、同步示例 程序 7 、同步示例 #include “mpi.h” #include “test.h” #include #include int main(int argc,char * * argv) { int rank,size,I; int rank,size,I; int *table; int *table; int errors=0; int errors=0; MPI_Aint address; MPI_Aint address; MPI_Datatype type,newtype; MPI_Datatype type,newtype; int lens; int lens; MPI_Init( &argc,&argv); MPI_Init( &argc,&argv); MPI_Comm_rank (MPI_COMM_WORLD,&rank); MPI_Comm_rank (MPI_COMM_WORLD,&rank); MPI_Comm_size (MPI_COMM_WORLD,&size); MPI_Comm_size (MPI_COMM_WORLD,&size);
 { int rank,size,I; int rank,size,I; int *table; int *table; int errors=0; int errors=0; MPI_Aint address; MPI_Aint address; MPI_Datatype type,newtype; MPI_Datatype type,newtype; int lens; int lens; MPI_Init( &argc,&argv); MPI_Init( &argc,&argv); MPI_Comm_rank (MPI_COMM_WORLD,&rank); MPI_Comm_rank (MPI_COMM_WORLD,&rank); MPI_Comm_size (MPI_COMM_WORLD,&size); MPI_Comm_size (MPI_COMM_WORLD,&size);")
24
/*Make data table */ /*Make data table */ table =(int *)calloc(size,sizeof(int)); table =(int *)calloc(size,sizeof(int)); table[rank]=rank+1; /* 准备要广播的数据 */ table[rank]=rank+1; /* 准备要广播的数据 */ MPI_Barrier (MPI_COMM_WORLD); MPI_Barrier (MPI_COMM_WORLD); /* 将数据广播出去 */ /* 将数据广播出去 */ for (i=0;i<size,i++) for (i=0;i<size,i++) MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); /* 检查接收到的数据的正确性 */ /* 检查接收到的数据的正确性 */ for (i=0;i<size,i++) for (i=0;i<size,i++) if (table[i]!=i+1) errors++; if (table[i]!=i+1) errors++; MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ …… …… /* 其他的计算 */ /* 其他的计算 */ MPI_Finalize(); MPI_Finalize();}
![/*Make data table */ /*Make data table */ table =(int *)calloc(size,sizeof(int)); table =(int *)calloc(size,sizeof(int)); table[rank]=rank+1; /* 准备要广播的数据 */ table[rank]=rank+1; /* 准备要广播的数据 */ MPI_Barrier (MPI_COMM_WORLD); MPI_Barrier (MPI_COMM_WORLD); /* 将数据广播出去 */ /* 将数据广播出去 */ for (i=0;i<size,i++) for (i=0;i<size,i++) MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); /* 检查接收到的数据的正确性 */ /* 检查接收到的数据的正确性 */ for (i=0;i<size,i++) for (i=0;i<size,i++) if (table[i]!=i+1) errors++; if (table[i]!=i+1) errors++; MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ …… …… /* 其他的计算 */ /* 其他的计算 */ MPI_Finalize(); MPI_Finalize();}](http://images.slideplayer.no/16/5154920/slides/slide_24.jpg "/*Make data table */ /*Make data table */ table =(int *)calloc(size,sizeof(int)); table =(int *)calloc(size,sizeof(int)); table[rank]=rank+1; /* 准备要广播的数据 */ table[rank]=rank+1; /* 准备要广播的数据 */ MPI_Barrier (MPI_COMM_WORLD); MPI_Barrier (MPI_COMM_WORLD); /* 将数据广播出去 */ /* 将数据广播出去 */ for (i=0;i<size,i++) for (i=0;i<size,i++) MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); MPI_Bcast( &table[i],1,MPI_INT,i,MPI_COMM_WORLD); /* 检查接收到的数据的正确性 */ /* 检查接收到的数据的正确性 */ for (i=0;i<size,i++) for (i=0;i<size,i++) if (table[i]!=i+1) errors++; if (table[i]!=i+1) errors++; MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ MPI_Barrier(MPI_COMM_WORLD); /* 检查完毕后执行一次同步 */ …… …… /* 其他的计算 */ /* 其他的计算 */ MPI_Finalize(); MPI_Finalize();}")
25
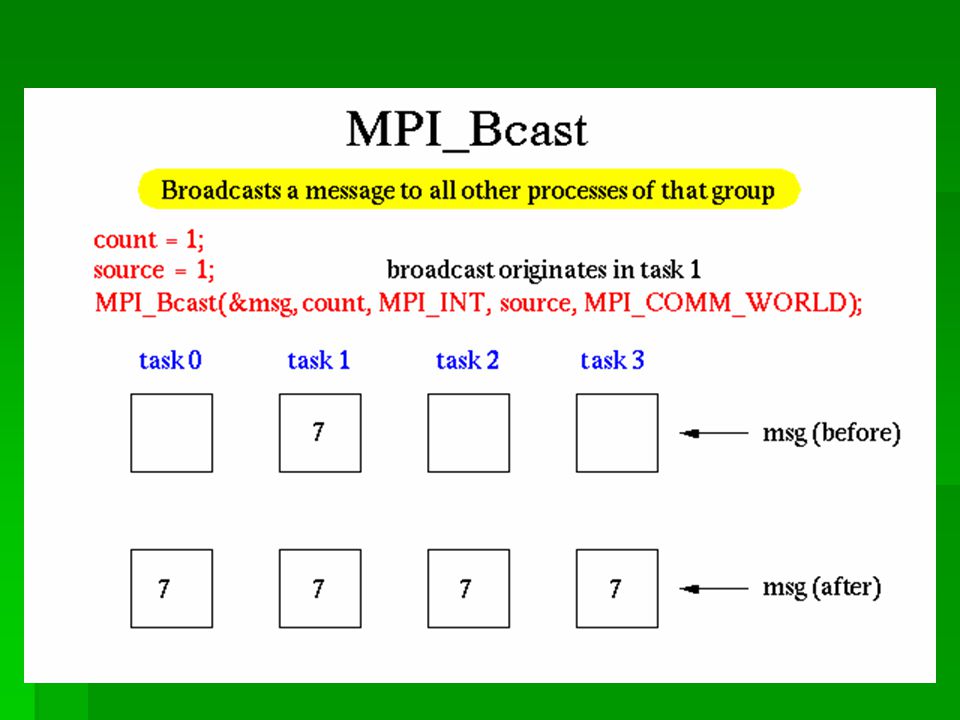
MPI_Bcast() MPI_Bcast() 从指定的一个根进程中把数据广播发送给组中 的所有其它进程: MPI_Bcast (*buffer,count,datatype,root,comm) 对于 root 进程: buffer 既是接收缓冲又是发送缓 冲;对于其他进程: buffer 就是接收缓冲。
 MPI_Bcast() 从指定的一个根进程中把数据广播发送给组中 的所有其它进程: MPI_Bcast (*buffer,count,datatype,root,comm) 对于 root 进程: buffer 既是接收缓冲又是发送缓 冲;对于其他进程: buffer 就是接收缓冲。")
27
程序 8 、广播程序示例 程序 8 、广播程序示例 #include #include #include “mpi.h” int main (argc,argv) int argc; Char * * argv; { int rank,value; int rank,value; MPI_Init(&argc,&argv); MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); MPI_Comm_rank(MPI_COMM_WORLD,&rank);
 int argc; Char * * argv; { int rank,value; int rank,value; MPI_Init(&argc,&argv); MPI_Init(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); MPI_Comm_rank(MPI_COMM_WORLD,&rank);")
28
do{ do{ if (rank==0) /* 进程 0 读入需要广播的数据 */ if (rank==0) /* 进程 0 读入需要广播的数据 */ scanf(“%d”,&value); scanf(“%d”,&value); /* 将该数据广播出去 */ /* 将该数据广播出去 */ MPI_Bcast(&value,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Bcast(&value,1,MPI_INT,0,MPI_COMM_WORLD); /* 各进程打印收到的数据 */ /* 各进程打印收到的数据 */ printf(“Process %d got %d \n”,rank,value); printf(“Process %d got %d \n”,rank,value); }while(value>=0); }while(value>=0); MPI_Finalize(); MPI_Finalize(); return 0; return 0;}
 /* 进程 0 读入需要广播的数据 */ if (rank==0) /* 进程 0 读入需要广播的数据 */ scanf( %d ,&value); scanf( %d ,&value); /* 将该数据广播出去 */ /* 将该数据广播出去 */ MPI_Bcast(&value,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Bcast(&value,1,MPI_INT,0,MPI_COMM_WORLD); /* 各进程打印收到的数据 */ /* 各进程打印收到的数据 */ printf( Process %d got %d \n ,rank,value); printf( Process %d got %d \n ,rank,value); }while(value>=0); }while(value>=0); MPI_Finalize(); MPI_Finalize(); return 0; return 0;}")
29
MPI_Scatter() MPI_Scatter() 把根进程中的数据分散发送给组中的所有进程 (包括自己): MPI_Scatter (*sendbuf,sendcnt,sendtype, *recvbuf, recvcnt,recvtype,root,comm) *recvbuf, recvcnt,recvtype,root,comm) root 用 MPI_Send(sendbuf, sendcount·n, sendtype, …) 发送一个消息。这个消息分成 n 个 相等的段,第 i 个段发送到进程组的第 i 个进程, sendcnt 必须要和 recvcnt 相同。 root 用 MPI_Send(sendbuf, sendcount·n, sendtype, …) 发送一个消息。这个消息分成 n 个 相等的段,第 i 个段发送到进程组的第 i 个进程, sendcnt 必须要和 recvcnt 相同。
 MPI_Scatter() 把根进程中的数据分散发送给组中的所有进程 (包括自己): MPI_Scatter (*sendbuf,sendcnt,sendtype, *recvbuf, recvcnt,recvtype,root,comm) *recvbuf, recvcnt,recvtype,root,comm) root 用 MPI_Send(sendbuf, sendcount·n, sendtype, …) 发送一个消息。这个消息分成 n 个 相等的段,第 i 个段发送到进程组的第 i 个进程, sendcnt 必须要和 recvcnt 相同。 root 用 MPI_Send(sendbuf, sendcount·n, sendtype, …) 发送一个消息。这个消息分成 n 个 相等的段,第 i 个段发送到进程组的第 i 个进程, sendcnt 必须要和 recvcnt 相同。")
31
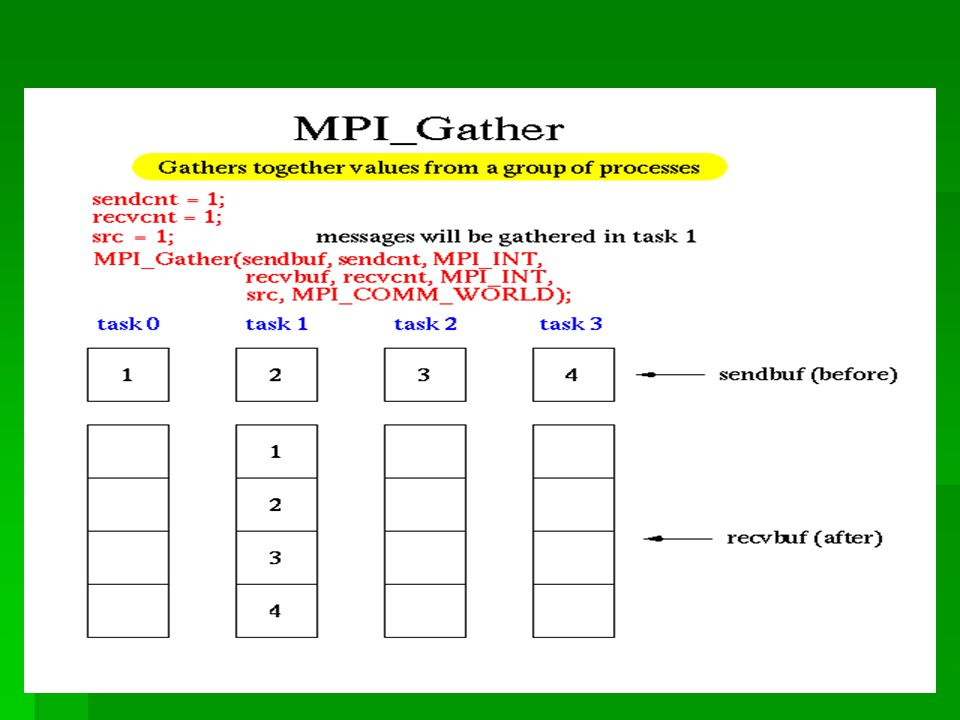
MPI_Gather() 在组中指定一个进程收集组中所有进程发送来的 消息,这个函数操作与 MPI_Scatter 函数操作相 反: MPI_Gather (*sendbuf,sendcnt,sendtype, *recvbuf, ecvcount,recvtype,root,comm) *recvbuf, ecvcount,recvtype,root,comm)
 在组中指定一个进程收集组中所有进程发送来的 消息,这个函数操作与 MPI_Scatter 函数操作相 反: MPI_Gather (*sendbuf,sendcnt,sendtype, *recvbuf, ecvcount,recvtype,root,comm) *recvbuf, ecvcount,recvtype,root,comm)")
33
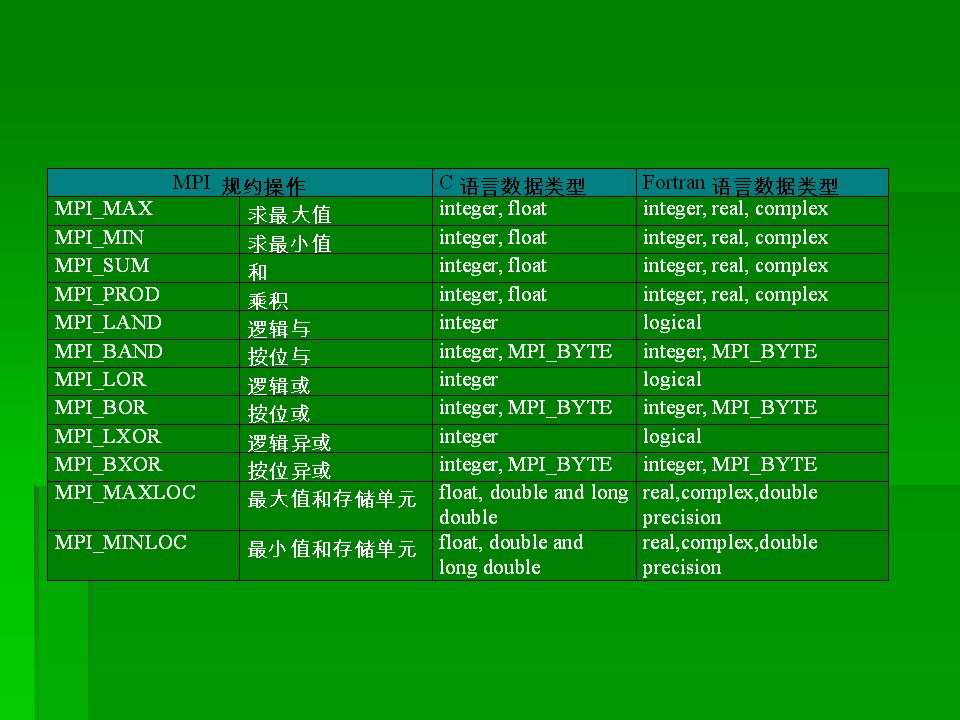
MPI_Reduce() MPI_Reduce() 在组内所有的进程中,执行一个规约操作,并 把结果存放在指定的一个进程中: MPI_Reduce (*sendbuf,*recvbuf,count,datatype, op,root, comm) op,root, comm) MPI 缺省定义了如下的规约操作,用户可根据 自己的需要用 MPI_Op_create 函数创建新的规 约操作:
 MPI_Reduce() 在组内所有的进程中,执行一个规约操作,并 把结果存放在指定的一个进程中: MPI_Reduce (*sendbuf,*recvbuf,count,datatype, op,root, comm) op,root, comm) MPI 缺省定义了如下的规约操作,用户可根据 自己的需要用 MPI_Op_create 函数创建新的规 约操作:")
35
程序 9 、规约示例 程序 9 、规约示例 #include “mpi.h” #include “mpi.h” #include #include double f(double x);/* 定义函数 f(x) */ double f(double x);/* 定义函数 f(x) */ { return(4.0/(1.0+x*x)); return(4.0/(1.0+x*x)); } int main (int argc,char * argv[]) int main (int argc,char * argv[]) { int done =0,n,myid,numprocs,i; int done =0,n,myid,numprocs,i; double PI25DT=3.141592653589793238462643; double PI25DT=3.141592653589793238462643; double mypi,pi,h,sum,x; double mypi,pi,h,sum,x; double startwtime=0.0,endwtime; double startwtime=0.0,endwtime; int namelen; int namelen; char processor_name[MPI_MAXPROCESSOR_NAME]; char processor_name[MPI_MAXPROCESSOR_NAME];
![程序 9 、规约示例 程序 9 、规约示例 #include mpi.h #include mpi.h #include #include double f(double x);/* 定义函数 f(x) */ double f(double x);/* 定义函数 f(x) */ { return(4.0/(1.0+x*x)); return(4.0/(1.0+x*x)); } int main (int argc,char * argv[]) int main (int argc,char * argv[]) { int done =0,n,myid,numprocs,i; int done =0,n,myid,numprocs,i; double PI25DT= ; double PI25DT= ; double mypi,pi,h,sum,x; double mypi,pi,h,sum,x; double startwtime=0.0,endwtime; double startwtime=0.0,endwtime; int namelen; int namelen; char processor_name[MPI_MAXPROCESSOR_NAME]; char processor_name[MPI_MAXPROCESSOR_NAME];](http://images.slideplayer.no/16/5154920/slides/slide_35.jpg "程序 9 、规约示例 程序 9 、规约示例 #include mpi.h #include mpi.h #include #include double f(double x);/* 定义函数 f(x) */ double f(double x);/* 定义函数 f(x) */ { return(4.0/(1.0+x*x)); return(4.0/(1.0+x*x)); } int main (int argc,char * argv[]) int main (int argc,char * argv[]) { int done =0,n,myid,numprocs,i; int done =0,n,myid,numprocs,i; double PI25DT= ; double PI25DT= ; double mypi,pi,h,sum,x; double mypi,pi,h,sum,x; double startwtime=0.0,endwtime; double startwtime=0.0,endwtime; int namelen; int namelen; char processor_name[MPI_MAXPROCESSOR_NAME]; char processor_name[MPI_MAXPROCESSOR_NAME];")
36
MPI_Init(&argc,&argv); MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Get_processor_name(processor_name,&namelen); MPI_Get_processor_name(processor_name,&namelen); fprint(stdout,”Process %d of %d on % s\n”,myid,numprocs, fprint(stdout,”Process %d of %d on % s\n”,myid,numprocs, processor_name); processor_name); n=0; n=0; if (myid==0) if (myid==0) { printf(“Please give N=”); printf(“Please give N=”); scanf(&n); scanf(&n); startwtime=MPI_Wtime(); startwtime=MPI_Wtime(); } /* 将 n 值广播出去 */ /* 将 n 值广播出去 */ MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Comm_rank(MPI_COMM_WORLD,&myid); MPI_Get_processor_name(processor_name,&namelen); MPI_Get_processor_name(processor_name,&namelen); fprint(stdout, Process %d of %d on % s\n ,myid,numprocs, fprint(stdout, Process %d of %d on % s\n ,myid,numprocs, processor_name); processor_name); n=0; n=0; if (myid==0) if (myid==0) { printf( Please give N= ); printf( Please give N= ); scanf(&n); scanf(&n); startwtime=MPI_Wtime(); startwtime=MPI_Wtime(); } /* 将 n 值广播出去 */ /* 将 n 值广播出去 */ MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD); MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);")
37
h=1.0/(double) n; h=1.0/(double) n; sum=0.0; sum=0.0; for(i=myid+1;i<=n;i+=numprocs) for(i=myid+1;i<=n;i+=numprocs) /* 每一个进程计算一部分矩形的面积,若进程总数 numprocs 为 4 , /* 每一个进程计算一部分矩形的面积,若进程总数 numprocs 为 4 , 将 0-1 区间划分为 100 个矩形,则各个进程分别计算矩形块 将 0-1 区间划分为 100 个矩形,则各个进程分别计算矩形块 0 进程 1 , 5 , 9 , 13 , …… , 97 0 进程 1 , 5 , 9 , 13 , …… , 97 1 进程 2 , 6 , 10 , 14 , …… , 98 1 进程 2 , 6 , 10 , 14 , …… , 98 2 进程 3 , 7 , 11 , 15 , …… , 99 2 进程 3 , 7 , 11 , 15 , …… , 99 3 进程 4 , 8 , 12 , 16 , …… , 100 */ 3 进程 4 , 8 , 12 , 16 , …… , 100 */ { x=h*((double)i-0.5); x=h*((double)i-0.5); sum+=f(x); sum+=f(x); } mypi=h*sum; /* 各进程并行计算得到的部分和 */ mypi=h*sum; /* 各进程并行计算得到的部分和 */
 n; h=1.0/(double) n; sum=0.0; sum=0.0; for(i=myid+1;i<=n;i+=numprocs) for(i=myid+1;i<=n;i+=numprocs) /* 每一个进程计算一部分矩形的面积,若进程总数 numprocs 为 4 , /* 每一个进程计算一部分矩形的面积,若进程总数 numprocs 为 4 , 将 0-1 区间划分为 100 个矩形,则各个进程分别计算矩形块 将 0-1 区间划分为 100 个矩形,则各个进程分别计算矩形块 0 进程 1 , 5 , 9 , 13 , …… , 97 0 进程 1 , 5 , 9 , 13 , …… , 97 1 进程 2 , 6 , 10 , 14 , …… , 98 1 进程 2 , 6 , 10 , 14 , …… , 98 2 进程 3 , 7 , 11 , 15 , …… , 99 2 进程 3 , 7 , 11 , 15 , …… , 99 3 进程 4 , 8 , 12 , 16 , …… , 100 */ 3 进程 4 , 8 , 12 , 16 , …… , 100 */ { x=h*((double)i-0.5); x=h*((double)i-0.5); sum+=f(x); sum+=f(x); } mypi=h*sum; /* 各进程并行计算得到的部分和 */ mypi=h*sum; /* 各进程并行计算得到的部分和 */")
38
/* 将部分和累加得到所有矩形的面积,该面积和即为近似 PI 值 */ /* 将部分和累加得到所有矩形的面积,该面积和即为近似 PI 值 */ MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0, MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0, MPI_COMM_WORLD); MPI_COMM_WORLD); if(myid==0) if(myid==0) { printf(“pi is approximately %.16f,Error is %.16f\n”, printf(“pi is approximately %.16f,Error is %.16f\n”, pi,fabs(pi-PI25DT)); pi,fabs(pi-PI25DT)); endwtime=MPI_Wtime(); endwtime=MPI_Wtime(); printf(“wall clock time=% f\n”,endwtime-startwtime); printf(“wall clock time=% f\n”,endwtime-startwtime); fflush(stdout); fflush(stdout); } MPI_Finalize(); MPI_Finalize(); }
; MPI_COMM_WORLD); if(myid==0) if(myid==0) { printf( pi is approximately %.16f,Error is %.16f\n , printf( pi is approximately %.16f,Error is %.16f\n , pi,fabs(pi-PI25DT)); pi,fabs(pi-PI25DT)); endwtime=MPI_Wtime(); endwtime=MPI_Wtime(); printf( wall clock time=% f\n ,endwtime-startwtime); printf( wall clock time=% f\n ,endwtime-startwtime); fflush(stdout); fflush(stdout); } MPI_Finalize(); MPI_Finalize(); }")
39
MPI_Scan() MPI_Scan() 用来对分布在进程组上的数据执行前缀归约: MPI_Scan (*sendbuf,*recvbuf,count, datatype,op,comm) datatype,op,comm)
 MPI_Scan() 用来对分布在进程组上的数据执行前缀归约: MPI_Scan (*sendbuf,*recvbuf,count, datatype,op,comm) datatype,op,comm)")
42
群集函数的特点: 群集函数的特点: 通讯因子中所有进程都要调用 除了 MPI_Barrier(), 其他函数使用类似标准阻 塞的通信模式。一个进程一旦结束了它所参 与的群集操作就从群集例程中返回,并不保 证其他进程执行该群集例程已经完成。 一个群集例程是不是同步操作取决于实现。
, 其他函数使用类似标准阻 塞的通信模式。一个进程一旦结束了它所参 与的群集操作就从群集例程中返回,并不保 证其他进程执行该群集例程已经完成。 一个群集例程是不是同步操作取决于实现。")
43
MPI 并行程序的两种基本模式 MPI 并行程序的两种基本模式 对等模式的 MPI 程序设计 主从模式的 MPI 程序设计

44
一. 对等模式的 MPI 程序设计 1. 问题描述 ——Jacobi 迭代 Jacobi 迭代是一种比较常见的迭代方法, 其核心部分可以用程序 1 来表示。简单的说, Jacobi 迭代得到的新值是原来旧值点相邻数 值点的平均。 Jacobi 迭代是一种比较常见的迭代方法, 其核心部分可以用程序 1 来表示。简单的说, Jacobi 迭代得到的新值是原来旧值点相邻数 值点的平均。 Jacobi 迭代的局部性很好,可以取得很高 的并行性。将参加迭代的数据按块分割后, 各块之间除了相邻的元素需要通信外,在各 块的内部可以完全独立的并行计算。 Jacobi 迭代的局部性很好,可以取得很高 的并行性。将参加迭代的数据按块分割后, 各块之间除了相邻的元素需要通信外,在各 块的内部可以完全独立的并行计算。

45
程序 10 串行表示的 Jacobi 迭代 程序 10 串行表示的 Jacobi 迭代 …… REAL A(N+1,N+1),B(N+1,N+1) …… DO K=1,STEP DO J=1,N DO J=1,N DO I=1,N DO I=1,N B(I,J)=0.25*(A(I-1,J)+A(I+1,J)+A(I,J+1)+A(I,J-1)) B(I,J)=0.25*(A(I-1,J)+A(I+1,J)+A(I,J+1)+A(I,J-1)) END DO END DO DO J=1,N DO J=1,N DO I=1,N DO I=1,N A(I,J)=B(I,J) A(I,J)=B(I,J) END DO END DO END DO
,B(N+1,N+1) …… DO K=1,STEP DO J=1,N DO J=1,N DO I=1,N DO I=1,N B(I,J)=0.25*(A(I-1,J)+A(I+1,J)+A(I,J+1)+A(I,J-1)) B(I,J)=0.25*(A(I-1,J)+A(I+1,J)+A(I,J+1)+A(I,J-1)) END DO END DO DO J=1,N DO J=1,N DO I=1,N DO I=1,N A(I,J)=B(I,J) A(I,J)=B(I,J) END DO END DO END DO")
46
2. 用 MPI 程序实现 Jacobi 迭代 2. 用 MPI 程序实现 Jacobi 迭代 为了并行求解,这里将参加迭代的数据按列进行分割,假设有 4 个进程同时并行计算,数据的分割结果如图:

47
假设需要迭代的数据是 M*M 的二维数组 A(M,M), 令 M=4*N, 按上 假设需要迭代的数据是 M*M 的二维数组 A(M,M), 令 M=4*N, 按上 图进行数据划分,则分布在 4 个不同进程上的数据分别是: 进程 0 : A(M,1:N); 进程 0 : A(M,1:N); 进程 1 : A(M,N+1:2*N); 进程 1 : A(M,N+1:2*N); 进程 2 : A(M,2*N+1:3*N); 进程 2 : A(M,2*N+1:3*N); 进程 3 : A(M,3*N+1:4*N). 进程 3 : A(M,3*N+1:4*N). 由于在迭代过程中,边界点新值的计算需要相邻边界其他块的 由于在迭代过程中,边界点新值的计算需要相邻边界其他块的 数据,因此在每一个数据块的两侧各增加 1 列的数据空间,用于 存放从相邻数据块通信得到的数据。每个数据块的大小就从 M*N 扩大到 M*(N+2) 。 计算和通信过程是这样的:首先对数组赋初值,边界赋为 8 , 计算和通信过程是这样的:首先对数组赋初值,边界赋为 8 , 内部为 0 。然后开始迭代,迭代之前,每个进程都需要从相邻的 进程得到数据块,同时也向相邻的进程提供数据块 (FORTRAN 数 组在内存中是按列优先排列的 ) 。
. 由于在迭代过程中,边界点新值的计算需要相邻边界其他块的 由于在迭代过程中,边界点新值的计算需要相邻边界其他块的 数据,因此在每一个数据块的两侧各增加 1 列的数据空间,用于 存放从相邻数据块通信得到的数据。每个数据块的大小就从 M*N 扩大到 M*(N+2) 。 计算和通信过程是这样的:首先对数组赋初值,边界赋为 8 , 计算和通信过程是这样的:首先对数组赋初值,边界赋为 8 , 内部为 0 。然后开始迭代,迭代之前,每个进程都需要从相邻的 进程得到数据块,同时也向相邻的进程提供数据块 (FORTRAN 数 组在内存中是按列优先排列的 ) 。.")
48
进程 0 进程 1 进程 2 进程 3 发送 接收

49
程序 11 、 并行的 Jacobi 迭代 程序 11 、 并行的 Jacobi 迭代 program main include ‘mpif.h’ integer totalsize,mysize,steps Parameter (totalsize=16) ( 定义全局数组的规模) parameter (mysize=totalsize/4,steps=10) integer n,myid,numprocs,i,j,rc Real a(totalsize,mysize+2),b(totalsize,mysize+2) Integer begin_col,end_col,ierr Integer status(MPI_STATUS_SIZE)
 ( 定义全局数组的规模) parameter (mysize=totalsize/4,steps=10) integer n,myid,numprocs,i,j,rc Real a(totalsize,mysize+2),b(totalsize,mysize+2) Integer begin_col,end_col,ierr Integer status(MPI_STATUS_SIZE)")
50
call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr) print *,”Process”,myid,” of”,numprocs,” is alive” ( 数组初始化 ) do j=1,mysize+2 do i=1,totalsize do i=1,totalsize a(i,j)=0.0 a(i,j)=0.0 end do end do end do If (myid.eq.0) then do i=1,totalsize do i=1,totalsize a(i,2)=8.0 a(i,2)=8.0 end do end do end if
 call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr) print *, Process ,myid, of ,numprocs, is alive ( 数组初始化 ) do j=1,mysize+2 do i=1,totalsize do i=1,totalsize a(i,j)=0.0 a(i,j)=0.0 end do end do end do If (myid.eq.0) then do i=1,totalsize do i=1,totalsize a(i,2)=8.0 a(i,2)=8.0 end do end do end if")
51
If (myid.eq.3) then do i=1,totalsize do i=1,totalsize a(i,mysize+1)=8.0 a(i,mysize+1)=8.0 end do end do end if If (myid.eq.3) then do i=1,totalsize do i=1,totalsize a(i,mysize+1)=8.0 a(i,mysize+1)=8.0 end do end do end if do i=1,mysize+2 a(1,i)=8.0 a(1,i)=8.0 a(totalsize,i)=8.0 a(totalsize,i)=8.0 end do
 then do i=1,totalsize do i=1,totalsize a(i,mysize+1)=8.0 a(i,mysize+1)=8.0 end do end do end if If (myid.eq.3) then do i=1,totalsize do i=1,totalsize a(i,mysize+1)=8.0 a(i,mysize+1)=8.0 end do end do end if do i=1,mysize+2 a(1,i)=8.0 a(1,i)=8.0 a(totalsize,i)=8.0 a(totalsize,i)=8.0 end do")
52
(Jacobi 迭代部分 ) do n=1,steps ( 从右侧的邻居得到数据 ) if (myid.lt.3)then if (myid.lt.3)then call MPI_RECV(a(1,mysize+2),totalsize,MPI_REAL,myid+1, call MPI_RECV(a(1,mysize+2),totalsize,MPI_REAL,myid+1, 10,MPI_COMM_WORLD,status,ierr) 10,MPI_COMM_WORLD,status,ierr) end if end if ( 向左侧的邻居发送数据 ) if (myid.gt.0)then if (myid.gt.0)then call MPI_SEND(a(1,2),totalsize,MPI_REAL,myid-1, call MPI_SEND(a(1,2),totalsize,MPI_REAL,myid-1, 10,MPI_COMM_WORLD,ierr) 10,MPI_COMM_WORLD,ierr) end if end if
 do n=1,steps ( 从右侧的邻居得到数据 ) if (myid.lt.3)then if (myid.lt.3)then call MPI_RECV(a(1,mysize+2),totalsize,MPI_REAL,myid+1, call MPI_RECV(a(1,mysize+2),totalsize,MPI_REAL,myid+1, 10,MPI_COMM_WORLD,status,ierr) 10,MPI_COMM_WORLD,status,ierr) end if end if ( 向左侧的邻居发送数据 ) if (myid.gt.0)then if (myid.gt.0)then call MPI_SEND(a(1,2),totalsize,MPI_REAL,myid-1, call MPI_SEND(a(1,2),totalsize,MPI_REAL,myid-1, 10,MPI_COMM_WORLD,ierr) 10,MPI_COMM_WORLD,ierr) end if end if")
53
// 向右侧的邻居发送数据 if (myid.lt.3) then if (myid.lt.3) then call MPI_SEND(a(1,mysize+1),totalsize,MPI_REAL,myid+1, call MPI_SEND(a(1,mysize+1),totalsize,MPI_REAL,myid+1, 10,MPI_COMM_WORLD,ierr) 10,MPI_COMM_WORLD,ierr) end if end if // 从左侧的邻居接收数据 if (myid.gt.0) then if (myid.gt.0) then call MPI_RECV(a(1,1),totalsize,MPI_REAL,myid-1, call MPI_RECV(a(1,1),totalsize,MPI_REAL,myid-1, 10,MPI_COMM_WORLD,status,ierr) 10,MPI_COMM_WORLD,status,ierr) end if end ifbegin_col=2end_col=mysize+1
 then if (myid.lt.3) then call MPI_SEND(a(1,mysize+1),totalsize,MPI_REAL,myid+1, call MPI_SEND(a(1,mysize+1),totalsize,MPI_REAL,myid+1, 10,MPI_COMM_WORLD,ierr) 10,MPI_COMM_WORLD,ierr) end if end if // 从左侧的邻居接收数据 if (myid.gt.0) then if (myid.gt.0) then call MPI_RECV(a(1,1),totalsize,MPI_REAL,myid-1, call MPI_RECV(a(1,1),totalsize,MPI_REAL,myid-1, 10,MPI_COMM_WORLD,status,ierr) 10,MPI_COMM_WORLD,status,ierr) end if end ifbegin_col=2end_col=mysize+1")
54
if (myid.eq.0) then begin_col=3 begin_col=3 end if end if if (myid.eq.3) then end_col=mysize end_col=mysize end if end if do j=begin_col,end_col do i=2,totalsize-1 do i=2,totalsize-1 b(i,j)=0.25*(a(i,j+1)+a(i,j-1)+a(i+1,j)+a(i-1,j)) b(i,j)=0.25*(a(i,j+1)+a(i,j-1)+a(i+1,j)+a(i-1,j)) end do end do
 then begin_col=3 begin_col=3 end if end if if (myid.eq.3) then end_col=mysize end_col=mysize end if end if do j=begin_col,end_col do i=2,totalsize-1 do i=2,totalsize-1 b(i,j)=0.25*(a(i,j+1)+a(i,j-1)+a(i+1,j)+a(i-1,j)) b(i,j)=0.25*(a(i,j+1)+a(i,j-1)+a(i+1,j)+a(i-1,j)) end do end do")
55
do j=begin_col,end_col do i=2,totalsize-1 do i=2,totalsize-1 a(i,j)=b(i,j) a(i,j)=b(i,j) end do end do end do do i=2,totalsize-1 print *,myid,(a(i,j),j=begin_col,end_col) print *,myid,(a(i,j),j=begin_col,end_col) end do call MPI_FINALIZE(rc) end
=b(i,j) a(i,j)=b(i,j) end do end do end do do i=2,totalsize-1 print *,myid,(a(i,j),j=begin_col,end_col) print *,myid,(a(i,j),j=begin_col,end_col) end do call MPI_FINALIZE(rc) end")
56
二. 主从模式的 MPI 程序设计 1. 问题描述 —— 矩阵向量乘 实现矩阵 C=A x B 。具体实现方法是:主进程将向量 B 广播 给所有的从进程,然后将矩阵 A 的各行依次发送给从进程, 从进程计算一行和 B 相乘的结果,然后将结果发送给主进程。 主进程循环向各个从进程发送一行的数据,直到将 A 各行的 数据发送完毕。一旦主进程将 A 的各行发送完毕,则每收到 一个结果,就向相应的从进程发送结束标志,从进程接收到 结束标志后退出执行。主进程收集完所有的结果后也结束。 实现矩阵 C=A x B 。具体实现方法是:主进程将向量 B 广播 给所有的从进程,然后将矩阵 A 的各行依次发送给从进程, 从进程计算一行和 B 相乘的结果,然后将结果发送给主进程。 主进程循环向各个从进程发送一行的数据,直到将 A 各行的 数据发送完毕。一旦主进程将 A 的各行发送完毕,则每收到 一个结果,就向相应的从进程发送结束标志,从进程接收到 结束标志后退出执行。主进程收集完所有的结果后也结束。

57
发送矩阵 A 的各行数据 回收各行与 B 相乘的结果 计算计算 计算计算 计算计算 计算计算 主进程 从进程

58
程序 12 、 矩阵向量乘 程序 12 、 矩阵向量乘 program main include “mpif.h” integer MAX_ROWS,MAX_COLS,rows,cols parameter (MAX_ROWS=1000,MAX_COLS=1000) double precision a(MAX_ROWS,MAX_COLS),b(MAX_COLS),c(MAX_COLS) double presicion buffer(MAX_COLS),ans integer myid,master,numprocs,ierr,status(MPI_STATUS_SIZE) integer i,j,numsent,numrcvd,sender integer anstype,row
 double precision a(MAX_ROWS,MAX_COLS),b(MAX_COLS),c(MAX_COLS) double presicion buffer(MAX_COLS),ans integer myid,master,numprocs,ierr,status(MPI_STATUS_SIZE) integer i,j,numsent,numrcvd,sender integer anstype,row")
59
call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr) master=0rows=100cols=100 If (myid.eq.master) then ( 主进程对矩阵 A 和 B 赋初值 ) ( 主进程对矩阵 A 和 B 赋初值 ) do i=1,cols do i=1,cols b(i)=1 b(i)=1 do j=1,rows do j=1,rows a(I,j)=1 a(I,j)=1 end do end do
 call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr) master=0rows=100cols=100 If (myid.eq.master) then ( 主进程对矩阵 A 和 B 赋初值 ) ( 主进程对矩阵 A 和 B 赋初值 ) do i=1,cols do i=1,cols b(i)=1 b(i)=1 do j=1,rows do j=1,rows a(I,j)=1 a(I,j)=1 end do end do")
60
numsent=0 numsent=0 numrcvd=0 numrcvd=0 ( 将矩阵 B 发送给所有其他的从进程,通过下面的广播语句实现 ) ( 将矩阵 B 发送给所有其他的从进程,通过下面的广播语句实现 ) call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, * MPI_COMM_WORLD,ierr) ( 依次将矩阵 A 的各行发送给其他的 numprocs-1 个从进程 ) ( 依次将矩阵 A 的各行发送给其他的 numprocs-1 个从进程 ) do i=1,min(numprocs-1,rows) do i=1,min(numprocs-1,rows) do j=1,cols do j=1,cols ( 将一行的数据取出来依次放到缓冲区中 ) ( 将一行的数据取出来依次放到缓冲区中 ) buffer(j)=a(i,j) buffer(j)=a(i,j) end do end do ( 将准备好的一行数据发送出去 ) ( 将准备好的一行数据发送出去 ) call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,i,i, call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,i,i, * MPI_COMM_WORLD,ierr) numsent=numsent+1 numsent=numsent+1 end do end do
 ( 将矩阵 B 发送给所有其他的从进程,通过下面的广播语句实现 ) call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, * MPI_COMM_WORLD,ierr) ( 依次将矩阵 A 的各行发送给其他的 numprocs-1 个从进程 ) ( 依次将矩阵 A 的各行发送给其他的 numprocs-1 个从进程 ) do i=1,min(numprocs-1,rows) do i=1,min(numprocs-1,rows) do j=1,cols do j=1,cols ( 将一行的数据取出来依次放到缓冲区中 ) ( 将一行的数据取出来依次放到缓冲区中 ) buffer(j)=a(i,j) buffer(j)=a(i,j) end do end do ( 将准备好的一行数据发送出去 ) ( 将准备好的一行数据发送出去 ) call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,i,i, call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,i,i, * MPI_COMM_WORLD,ierr) numsent=numsent+1 numsent=numsent+1 end do end do")
61
( 对所有的行,依次接收从进程对一行数据的计算结果 ) ( 对所有的行,依次接收从进程对一行数据的计算结果 ) do i=1,row do i=1,row call MPI_RECV(ans,1,MPI_DOUBLE_PRECISION,MPI_ANY_SOURCE, call MPI_RECV(ans,1,MPI_DOUBLE_PRECISION,MPI_ANY_SOURCE, * MPI_ANY_TAG,MPI_COMM_WORLD,status,ierr) sender=status(MPI_SOURCE) sender=status(MPI_SOURCE) anstype=status(MPI_TAG) anstype=status(MPI_TAG) ( 将该行数据赋给结果数组 C 的相应单元 ) ( 将该行数据赋给结果数组 C 的相应单元 ) c(anstype)=ans c(anstype)=ans ( 如果还有其他的行没有被计算,则继续发送 ) ( 如果还有其他的行没有被计算,则继续发送 ) if (numsent.lt.rows) then if (numsent.lt.rows) then do j=1,cols do j=1,cols ( 准备好新一行的数据 ) ( 准备好新一行的数据 ) buffer(j)=a(numsent+1,j) buffer(j)=a(numsent+1,j) end do end do ( 将该行数据发送出去 ) ( 将该行数据发送出去 ) call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,sender, call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,sender, * numsent+1,MPI_COMM_WORLD,ierr) numsent=numsent+1 numsent=numsent+1
 ( 对所有的行,依次接收从进程对一行数据的计算结果 ) do i=1,row do i=1,row call MPI_RECV(ans,1,MPI_DOUBLE_PRECISION,MPI_ANY_SOURCE, call MPI_RECV(ans,1,MPI_DOUBLE_PRECISION,MPI_ANY_SOURCE, * MPI_ANY_TAG,MPI_COMM_WORLD,status,ierr) sender=status(MPI_SOURCE) sender=status(MPI_SOURCE) anstype=status(MPI_TAG) anstype=status(MPI_TAG) ( 将该行数据赋给结果数组 C 的相应单元 ) ( 将该行数据赋给结果数组 C 的相应单元 ) c(anstype)=ans c(anstype)=ans ( 如果还有其他的行没有被计算,则继续发送 ) ( 如果还有其他的行没有被计算,则继续发送 ) if (numsent.lt.rows) then if (numsent.lt.rows) then do j=1,cols do j=1,cols ( 准备好新一行的数据 ) ( 准备好新一行的数据 ) buffer(j)=a(numsent+1,j) buffer(j)=a(numsent+1,j) end do end do ( 将该行数据发送出去 ) ( 将该行数据发送出去 ) call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,sender, call MPI_SEND(buffer,cols,MPI_DOUBLE_PRECISION,sender, * numsent+1,MPI_COMM_WORLD,ierr) numsent=numsent+1 numsent=numsent+1")
62
else else ( 若所有行都已发送出去,则每接收一个消息则向相应的从进程发 ( 若所有行都已发送出去,则每接收一个消息则向相应的从进程发 送一个标志为 0 的空消息,终止该从进程的执行 ) 送一个标志为 0 的空消息,终止该从进程的执行 ) call MPI_SEND(1.0,0,MPI_DOUBLE_PRECISION,sender,0, call MPI_SEND(1.0,0,MPI_DOUBLE_PRECISION,sender,0, * MPI_COMM_WORLD,ierr) end if end if end do end doelse ( 下面为从进程的执行步骤,首先是接收数组 B) ( 下面为从进程的执行步骤,首先是接收数组 B) call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, * MPI_COMM_WORLD,ierr) ( 接收主进程发送过来的矩阵 A 一行的数据 ) ( 接收主进程发送过来的矩阵 A 一行的数据 ) call MPI_RECV(buffer,cols,MPI_DOUBLE_PRECISION,master, call MPI_RECV(buffer,cols,MPI_DOUBLE_PRECISION,master, * MPI_ANY_TAG,MPI_COMM_WORLD,status,ierr)
 送一个标志为 0 的空消息,终止该从进程的执行 ) call MPI_SEND(1.0,0,MPI_DOUBLE_PRECISION,sender,0, call MPI_SEND(1.0,0,MPI_DOUBLE_PRECISION,sender,0, * MPI_COMM_WORLD,ierr) end if end if end do end doelse ( 下面为从进程的执行步骤,首先是接收数组 B) ( 下面为从进程的执行步骤,首先是接收数组 B) call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, call MPI_BCAST(b,cols,MPI_DOUBLE_PRECISION,master, * MPI_COMM_WORLD,ierr) ( 接收主进程发送过来的矩阵 A 一行的数据 ) ( 接收主进程发送过来的矩阵 A 一行的数据 ) call MPI_RECV(buffer,cols,MPI_DOUBLE_PRECISION,master, call MPI_RECV(buffer,cols,MPI_DOUBLE_PRECISION,master, * MPI_ANY_TAG,MPI_COMM_WORLD,status,ierr)")
63
( 若接收到标志为 0 的消息,则退出执行 ) ( 若接收到标志为 0 的消息,则退出执行 ) if (status(MPI_TAG).ne.0) then if (status(MPI_TAG).ne.0) then row=status(MPI_TAG) row=status(MPI_TAG) ans=0.0 ans=0.0 do I=1,cols do I=1,cols ans=ans+buffer(i)*b(j) ans=ans+buffer(i)*b(j) end do end do ( 计算一行的结果,并将结果发送给主进程 ) ( 计算一行的结果,并将结果发送给主进程 ) call MPI_SEND(ans,1,MPI_DOUBLE_PRECISION,master,row, call MPI_SEND(ans,1,MPI_DOUBLE_PRECISION,master,row, MPI_COMM_WORLD,ierr) MPI_COMM_WORLD,ierr) goto 90 goto 90 end if end if end if call MPI_FINALIZE(ierr) end
 ( 若接收到标志为 0 的消息,则退出执行 ) if (status(MPI_TAG).ne.0) then if (status(MPI_TAG).ne.0) then row=status(MPI_TAG) row=status(MPI_TAG) ans=0.0 ans=0.0 do I=1,cols do I=1,cols ans=ans+buffer(i)*b(j) ans=ans+buffer(i)*b(j) end do end do ( 计算一行的结果,并将结果发送给主进程 ) ( 计算一行的结果,并将结果发送给主进程 ) call MPI_SEND(ans,1,MPI_DOUBLE_PRECISION,master,row, call MPI_SEND(ans,1,MPI_DOUBLE_PRECISION,master,row, MPI_COMM_WORLD,ierr) MPI_COMM_WORLD,ierr) goto 90 goto 90 end if end if end if call MPI_FINALIZE(ierr) end")
Liknende presentasjoner


, *fip( ), (*pfi) ( ); Erklærer en integer, en pointer til.>")



 橋本大也 (株)ネットエイジグループ チーフエバンジェリスト.>")
![LHU_ME 魏慶隆 李瑞宗老師 零件組立之基本操作 零件組立之步驟 Component Assembly [ 選取零件 ] 定位 定位指令說明 定位指令說明.](/15/4830687/big_thumb.jpg "LHU_ME 魏慶隆 李瑞宗老師 零件組立之基本操作 零件組立之步驟 Component Assembly [ 選取零件 ] 定位 定位指令說明 定位指令說明.>")







. 一、引言 从绿色革命到绿色科技 20 世纪 60 年代 “ 绿色革命 ” 的结果: 农作物高产 高产水稻品种 化肥大量使用烈性农药 水土污染、 肥力降低 水荒.>")


 翻譯出來﹐翻出來的就是我們看到的.>")
. 2 學習目標 1. 了解收益管理在供應鏈中所扮演的角色。 2. 界定出何種收益管理做法具有效率的情況。 3. 描述制定收益管理決策時,需要考量的取捨條 件。>")

