Laste ned presentasjonen
Presentasjon lastes. Vennligst vent

1
Siste forelesning er i morgen!
Oppsummeringsforelesning den 5.mai flyttes til fredag 29.april kl Holdes i dette auditoriet

2
Slutningsstatistikk PSY 1010

3
Utvalg og populasjon Populasjon: alle enhetene i universet vi definerer, f eks: - Alle over 18 år i Norge (3,5 mill) Utvalg: avgrenset del av populasjonen - 200 personer over 18 år Populajson Utvalg

4
Eksempel: IQ gjennomsnittsskårer i populasjon og utvalg
I populasjonen er og s = 15 Du trekker tre utvalg á 25 tilfeldige personer fra denne populasjonen og beregner : Utvalg 1: Utvalg Utvalg Utvalgsfeil (tilfeldigheter) = 3 = 1 = -2
 = = = -2.")
5
Utvalgsfeil (sampling error)
Utvalgets gjennomsnittsverdi (evt. prosentverdi) vil sannsynligvis avvike fra den ”sanne” verdien i populasjonen Vi må derfor regne med at en viss usikkerhet i de verdiene vi har regnet oss fram til basert på utvalget Vi må ta hensyn til denne feilmarginen hvis vi vil slutte noe om populasjonen ut i fra utvalget
 vil sannsynligvis avvike fra den sanne verdien i populasjonen. Vi må derfor regne med at en viss usikkerhet i de verdiene vi har regnet oss fram til basert på utvalget. Vi må ta hensyn til denne feilmarginen hvis vi vil slutte noe om populasjonen ut i fra utvalget.")
6
Utvalgsfordeling og standardfeil
Utvalgsfordeling (Sampling distribution): fordeling over gjennomsnittsnittsverdier til et uendelig antall utvalg trukket fra en populasjon Standardavviket i en utvalgsfordeling kalles standardfeil (standard error) Gir et mål på størrelsen på statistisk usikkerhet Standardfeilen (SX) er en funksjon av to ting: S : Hvor stort standardavviket i populasjonen er N: Størrelsen på utvalget
: fordeling over gjennomsnittsnittsverdier til et uendelig antall utvalg trukket fra en populasjon. Standardavviket i en utvalgsfordeling kalles standardfeil (standard error) Gir et mål på størrelsen på statistisk usikkerhet. Standardfeilen (SX) er en funksjon av to ting: S : Hvor stort standardavviket i populasjonen er. N: Størrelsen på utvalget.")
7
Normalfordelig og utvalgsfeil
50 % av utvalgenes gjennomsnittsverdier ligger under populasjonsgjennomsnittet 50 % ligger over 13,6% 34,1% 2,2 % 0,1 % -3 sX sX sX X sX sX sX

8
Standardfeil ved ulike utvalgsstørrelser
Utgangspunktet for eksempelet er at alle utvalg er trukket fra en populasjon med et standardavvik (s) på 15 N = 9 N = 25 N = 100 Altså: Størrelsen på utvalget påvirker hvor størrelsen på standardfeilen
 på 15. N = 9. N = 25. N = 100. Altså: Størrelsen på utvalget påvirker hvor størrelsen på standardfeilen.")
9
Utvalgsfordeling med ulike utvalgsstørrelser Alle utvalg er trukket fra samme populasjon
Uendelig antall utvalg med: En person skårer 115 poeng på en IQ test med m= 100 og sd = 15. Målt i prosent, hvor mange skårer laver enn personene i populasjonen? Hvor mange skårer bedre?

10
IQ og morsmelk Populasjonsgjennomsittet på IQ for 12 åringer er 100 og standardavviket er 15 En forsker har en hypotese om at morsmelk bidrar til høyere IQ Et 25 utvalg på 12-åringer som er blitt ammet fram til 2 års alder har i snitt en IQ skåre på 103 Hvor sannsynlig er det at disse har fått = 103 ved en ren tilfeldighet?

11
Hypotesetesting Nullhypotese (H0):
Det er ingen forskjell i IQ i populasjonen mellom barns om er ammet fram til 2 års alder og de som ikke er det Dvs: forskjell skyldes utvalgsfeil / tilfeldigheter Forskningshypotese (H1): Det er en forskjell i IQ i populasjonen mellom barns som er ammet fram til 2 års-alder og andre barn Hvor sannsynlig er det at en forskjell på 3 poeng eller mer skyldes en tilfeldighet? Denne benevnes som p-verdi
: Det er en forskjell i IQ i populasjonen mellom barns som er ammet fram til 2 års-alder og andre barn. Hvor sannsynlig er det at en forskjell på 3 poeng eller mer skyldes en tilfeldighet Denne benevnes som p-verdi.")
12
Normalfordelig og utvalgsfeil
Utvalgets = 103 13,6% 34,1% 2,2 % 0,1 % -3 sX sX sX X sX sX sX

13
Signifikanstesting Hvor sannsynlig det er at resultatet skyldes en tilfeldighet ved utvalget (utvalgsfeil)? I vårt eksempel: en på 103 eller høyere forekommer i 15,9 % av tilfellene vi trekker utvalg med N=25 fra populasjonen (p= 0.159) Grense for å forkaste nullhypotesen kalles signifikansnivå () : Vanlig grense: mindre enn 5 % sannsynlighet for at resultatet skyldes en tilfeldighet ( = 0.05) Kan også være strengere f eks mindre enn 1 % ( = 0.01) Hvis sjansen for at resultatet skyldes en tilfeldighet er større en signifikansnivået, beholdes nullhypotesen (H0)
 Grense for å forkaste nullhypotesen kalles signifikansnivå () : Vanlig grense: mindre enn 5 % sannsynlighet for at resultatet skyldes en tilfeldighet ( = 0.05) Kan også være strengere f eks mindre enn 1 % ( = 0.01) Hvis sjansen for at resultatet skyldes en tilfeldighet er større en signifikansnivået, beholdes nullhypotesen (H0)")
14
Type I og type II feil Aldri 100% sikre på at vi gjør riktig beslutning om å beholde eller forkaste nullhypotesen: I “virkeligheten”: Funnet skyldes en tilfeldighet Funnet skyldes ikke en tilfeldighet, er reelt Behold nullhypotesen Riktig beslutning Type II-feil Forkast nullhypotesen Type I-feil (α)
")
15
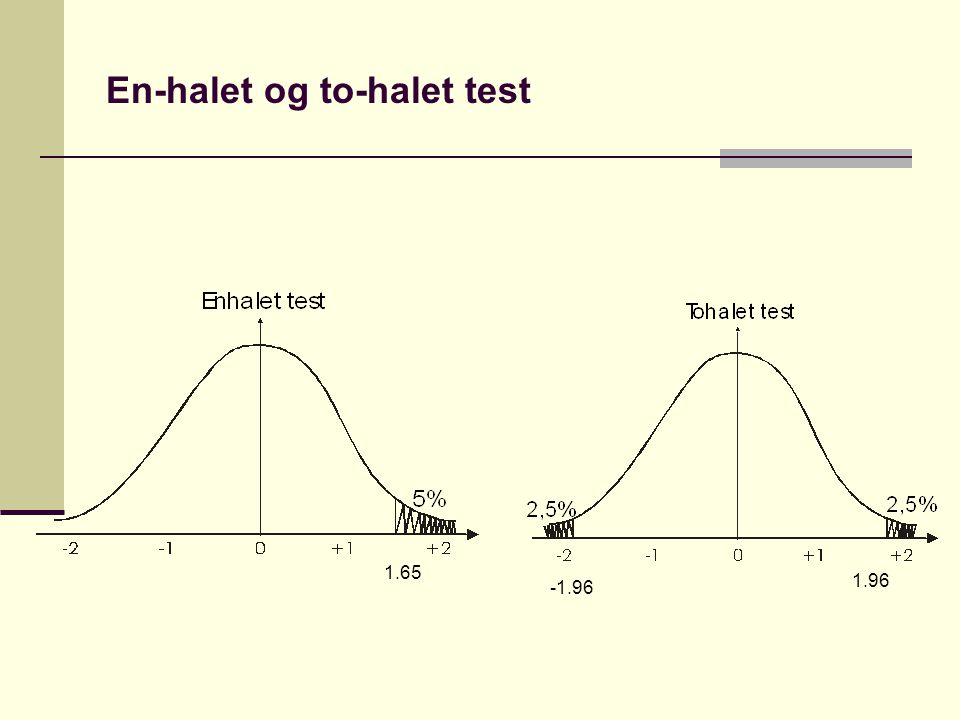
Enhalet og tohalet hypotesetest
En enhalet hypotesetest er retningsbestemt H1 : Barn som ammes fram til 2 år har høyere IQ enn andre En tohalet hypotesetest er ikke retningsbestemt H1 : Barn som ammes fram til 2 år har forskjellig IQ enn andre (dette betyr at de kan har lavere IQ eller høyere IQ enn populasjonen)
")
16
En-halet og to-halet test
1.65 1.96 -1.96
17
Hypotesetesting II Eksempel: Vi sammenligner et utvalg menn (N = 36) med et utvalg kvinner (n = 36) på en test for sosial intelligens. Vi får følgende Nullhypotese (H0): Det er ingen forskjell mellom menn og kvinner I populasjonen (forskjellen skyldes utvalgsfeil) Forskningshypotese (H1): Det er en forskjell i sosial IQ mellom menn og kvinner i populasjonen Hvor sannsynlig er det at forskjellen på 5 poeng skyldes en tilfeldighet? Denne benevnes som p-verdi
 med et utvalg kvinner (n = 36) på en test for sosial intelligens. Vi får følgende. Nullhypotese (H0): Det er ingen forskjell mellom menn og kvinner I populasjonen (forskjellen skyldes utvalgsfeil) Forskningshypotese (H1): Det er en forskjell i sosial IQ mellom menn og kvinner i populasjonen. Hvor sannsynlig er det at forskjellen på 5 poeng skyldes en tilfeldighet Denne benevnes som p-verdi.")
18
Parametriske hypotesetester
Eksemplene vi har gjennomgått nå er såkalt parametrisk statistikk. Dette forutsetter at: Utvalget er tilfeldig trukket fra populasjonen Utvalgsfordelingen er normalfordelt rundt populasjonsgjennomsnittet Et tilleggskriterium (kan dog korrigeres for): Hvis to eller flere utvalg sammenlignes, skal spredingen innen utvalgene være like
: Hvis to eller flere utvalg sammenlignes, skal spredingen innen utvalgene være like.")
19
Eksempler på parametriske tester
Z-test er et utvalgs gjennomsnittsverdi forskjellig fra populasjonsgjennomsnittet? t-test Er det forskjell i gjennomsnittsverdi mellom to utvalg? ANOVA (analysis og varians) Forskjell i gj.snittsverdi mellom tre eller flere utvalg? To-veis ANOVA
 Forskjell i gj.snittsverdi mellom tre eller flere utvalg To-veis ANOVA.")
20
Ikke-parametriske tester
Benyttes ofte når vi har variabler som er målt på nominal eller ordinalnivå Eller når forutsetningene for en parametrisk test ikke er oppfylt Benytter ellers samme logikk som tidligere, dvs. tar hensyn til utvalgsfeil/tilfeldighetenes spill og vurderer resultatene opp i mot dette

21
Eksempel på ikke-parametrisk test
Er det lettere for en person med lys hudfarge å bli frikjent enn en med mørk hudfarge for en voldsforbrytelse? Begge variablene (hudfarge og frikjent/dømt) er variabler som vi ikke kan regne gjennomsnitt på Frikjent Dømt Lys hudfarge 7 3 Mørk hudfarge 2 8 I dette tilfellet benyttes en kji-kvadrat test (2) for å avgjøre om forskjellen er tilfeldig eller ikke
 er variabler som vi ikke kan regne gjennomsnitt på. Frikjent. Dømt. Lys hudfarge Mørk hudfarge I dette tilfellet benyttes en kji-kvadrat test (2) for å avgjøre om forskjellen er tilfeldig eller ikke.")
22
Signifikansnivå og praktisk betydning
Et signifikant resultat er ikke nødvendigvis av stor praktisk betydning Dette er først og fremst fordi signifikanstesting er sterkt påvirket av utvalgets/utvalgenes størrelse Store utvalg = lettere å få signifikant resultat (forkaste H0) Et alternativ er å inkludere mål på effekt isteden, f eks hvor stor andel kvinner har høyere sosial IQ enn menn Eller hvor mange standardavvik skårer kvinner over menn
 Et alternativ er å inkludere mål på effekt isteden, f eks hvor stor andel kvinner har høyere sosial IQ enn menn. Eller hvor mange standardavvik skårer kvinner over menn.")
Liknende presentasjoner



















 a)P(T>1)=P(T≠1)=1-P(T=1) = 1-1/6 = 5/6 ≈ 83.3%. Evt. P(T>1)=p(T=2)+P(T=3)+P(T=4)+P(T=5)+ P(T=6)=5/6. P(T=2 | T≠1) = P(T=2 og T≠1)/P(T≠1) = (1/6)/(5/6)>")